
Scaling a Global MMO Card Game: From Regional Launch to Worldwide Infrastructure
Imagine this: You and your team have just launched an innovative, online multiplayer card game inspired by a culturally rich, fictional regional character. The game is a dynamic mix of strategy, collection, and battle — allowing players to trade, discover, and purchase unique digital cards while engaging in fast-paced modes like battle royale, duels, and limited-time challenges.
Initially, the deployment is lean and focused. The service is launched in a single cloud region — let’s say Asia Pacific — targeting your home market. Latency is low, gameplay is seamless, and the player base starts growing steadily. Encouraged by positive reception and viral social buzz, the game begins gaining traction not just locally, but in neighboring countries as well.
As media coverage spreads and influencers begin streaming gameplay, your user base begins to snowball. Players from Europe, the Americas, and Africa start logging in. What began as a regional game now faces the growing pains of becoming a global sensation.
Phase One: The Original Architecture
In the early phase, your system architecture was designed to support moderate, localized traffic. Here’s a simplified overview of that architecture:
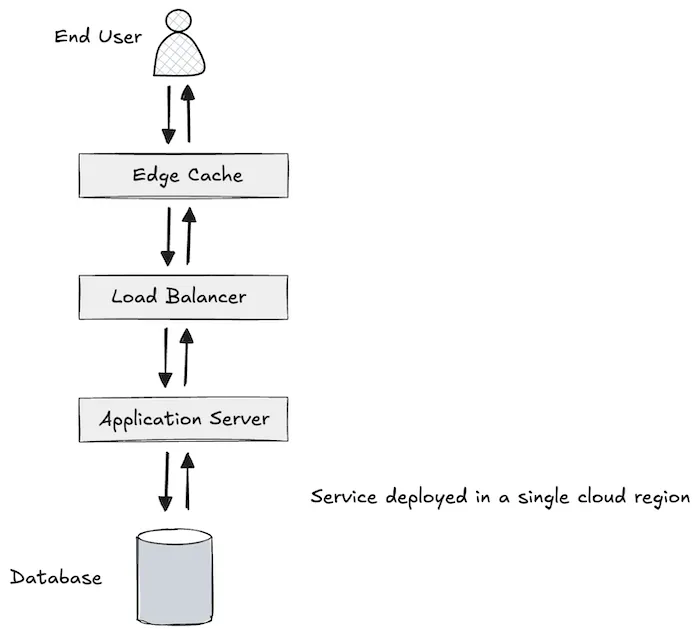
- Content Delivery Network (CDN): Deployed at the edge to deliver static assets like images, CSS, and JavaScript quickly and reliably to users.
- Application Server: Manages all the critical game logic including matchmaking, user actions, card trading logic, and real-time game state management.
- Primary Database: Stores all persistent data — player profiles, inventories, in-game economy, leaderboards, and the evolving state of live games.
You might also have:
- Cloud object storage for card artwork and battle replays.
- Search services to help players find cards or opponents.
- Queueing systems for asynchronous tasks and analytics.
- A matchmaking engine to pair players of similar skill levels.
This setup works beautifully — until it doesn’t.
Phase Two: The Global Stress Test
As the game gains global popularity, players from distant regions (e.g., Europe, North America, South America) start experiencing significant latency spikes. Why?
Because every read and write request is still routed to the original Asia Pacific cloud region.
The impact is twofold:
- Network Latency: Round-trip requests from faraway geographies to a single cloud region add hundreds of milliseconds — or more — to each action.
- System Bottlenecks: The central infrastructure begins to buckle under the load, especially during peak hours or high-intensity matches. Database CPU usage spikes, queues get backed up, and worst of all — users begin complaining.
In a genre where every millisecond matters, degraded latency isn’t just an inconvenience — it’s a business risk. Lag ruins immersion, unbalances competitive play, and drives users to competing games with smoother experiences.
Phase Three: The Need for a Distributed Strategy
To resolve this, a clear solution emerges: go global with infrastructure.
Distributing your services across multiple cloud regions becomes essential, not optional. The primary goal is to minimize latency by moving computation and data closer to the user — a strategy that not only improves performance but also increases resilience and scalability.
But distributing the application layer is relatively easy compared to the challenge of distributing the data layer. Your game needs to synchronize player data, leaderboards, inventory changes, and game progress across regions — without sacrificing consistency, availability, or responsiveness.
What’s Next: Exploring Global Database Distribution
Rather than going deep into multiplayer gaming architecture, this post sets the stage for the more pressing architectural concern: how do you scale your data architecture across multiple cloud regions?
You need a strategy that balances:
- Data consistency: Players can’t lose progress due to synchronization lags.
- Write locality: Minimize write latency while ensuring data is updated globally.
- Global reads: Let players access data fast, no matter their region.
- Cost-efficiency: Avoid the trap of duplicating expensive infrastructure everywhere.
In upcoming sections, we’ll explore models such as:
- Active-passive replication across regions.
- Geo-partitioned databases with smart routing.
- Conflict-free replicated data types (CRDTs) and eventual consistency techniques.
What started as a regional passion project now demands the robustness of internet-scale engineering. Scaling an MMO card game globally isn’t just about handling more players — it’s about re-architecting how data moves, lives, and evolves across continents.
As you expand into a multi-region cloud deployment, your next frontier is mastering global data distribution — the true backbone of a seamless, low-latency gaming experience. Let’s dive deeper into how we get there.
Designing a Cross-Cloud Region Distributed Service Architecture
As our multiplayer card game evolves from a regional success to a global sensation, one of the most critical architectural shifts involves extending infrastructure across multiple cloud regions. This is a pivotal move in minimizing user latency, maximizing uptime, and delivering consistent, responsive gameplay — no matter where the user is located.
To support our growing global audience, we must reimagine our architecture into a multi-region, resilient service fabric. Let’s break down how this transformation unfolds.
Step One: CDN and Application Layer Distribution
We start by extending our Content Delivery Network (CDN) presence across global edge locations. By doing so, we ensure that static assets (e.g., UI elements, images, JavaScript files) are served with minimal latency — regardless of geography.
Next, we deploy application servers in each major cloud region (e.g., Asia Pacific, Europe, North America). These servers are set up across multiple availability zones (AZs) within each region to ensure redundancy, availability, and fault tolerance.
This architecture allows for localized processing of game logic, reducing the round-trip time for user actions and significantly improving gameplay responsiveness.
Step Two: Intelligent Load Balancing
At the network layer, we implement a two-tiered load balancing strategy:
-
Global Load Balancer (GLB): Acts as the traffic controller for all incoming requests. It routes players to the nearest healthy cloud region based on their geolocation, latency metrics, or regional availability. If a region experiences downtime, the GLB fails over traffic to the next best region, ensuring uninterrupted service.
-
Regional Load Balancer (RLB): Within each cloud region, the RLB distributes traffic across the available zones and data centers. This enhances local fault tolerance and allows for smooth autoscaling within that region.
Curious about how CDN and load balancer layers work together? Check out CDN and Load Balancers (Understanding the request flow) for an in-depth breakdown of request routing.
Step Three: The Data Layer Challenge
Now we reach the most complex and critical part of the architecture: the database strategy.
Unlike application servers, which are stateless and easy to scale across regions, databases carry state — user data, game state, card ownership, inventories, transactions, leaderboards. This raises critical questions:
- Should we deploy independent databases per cloud region, storing only regional data?
- Can we shard the database, assigning each region a partition of the global data?
- Would read replicas in each cloud region improve latency for read-heavy operations?
The Short Answer: It Depends.
There is no one-size-fits-all answer here. The optimal database topology depends on the following factors:
- Game mechanics: Are players interacting across regions in real time? Do game objects (cards, resources) need global consistency?
- Latency sensitivity: Is low latency essential for every operation (e.g., in ranked battles)?
- Data residency: Do local laws mandate that user data be stored within specific geographic regions?
- Write patterns: Are writes high-volume, high-frequency (e.g., real-time leaderboards), or more episodic?
- Operational complexity: Can your team manage and monitor multi-region synchronization reliably?
Options at a Glance
-
Region-Specific Databases: Each region has its own database storing localized user data. Easier to manage and low-latency for regional users, but doesn’t support cross-region interactions well.
-
Global Sharded Database: Data is partitioned across regions based on user ID or geography. Good for scalability, but requires complex coordination logic and sharding strategy.
-
Read Replicas Across Regions: Primary writes go to a centralized region, while regional replicas serve reads. Ideal for read-heavy operations, but write latency remains an issue.
-
Multi-Master Replication / CRDTs: Advanced options for conflict resolution and distributed consensus. Offers global consistency, but comes with high complexity and operational risk.
Expanding to a cross-cloud region architecture is essential for any real-time, globally adopted game or application. While CDNs, application servers, and load balancers can be expanded relatively easily, the real challenge — and the real differentiator — lies in how you manage distributed data.
Striking the right balance between performance, reliability, cost, and complexity is key. In future posts, we’ll explore real-world strategies for global database distribution, data synchronization, and eventual consistency in MMO and high-scale applications.
Distributing the Database Across Cloud Regions: Leveraging Read Replicas
As we scale our multiplayer game to accommodate players across the globe, one of the most impactful ways to reduce latency and enhance the user experience is to strategically distribute our database layer. While spreading our application servers and CDNs across regions is fairly straightforward, ensuring fast and reliable access to dynamic data is far more complex — especially when it comes to reads and writes.
One common and effective strategy is to introduce read replicas into our multi-region architecture. These are database instances that mirror the data from a primary database — typically hosted in the central or main cloud region — and are deployed in secondary regions around the world.
What Are Read Replicas?
Read replicas are read-only copies of the primary database that synchronize data asynchronously (or sometimes synchronously) from the primary source. These replicas reside in geographically distributed cloud regions, allowing users in those regions to query local data rather than sending every request back to the central database.
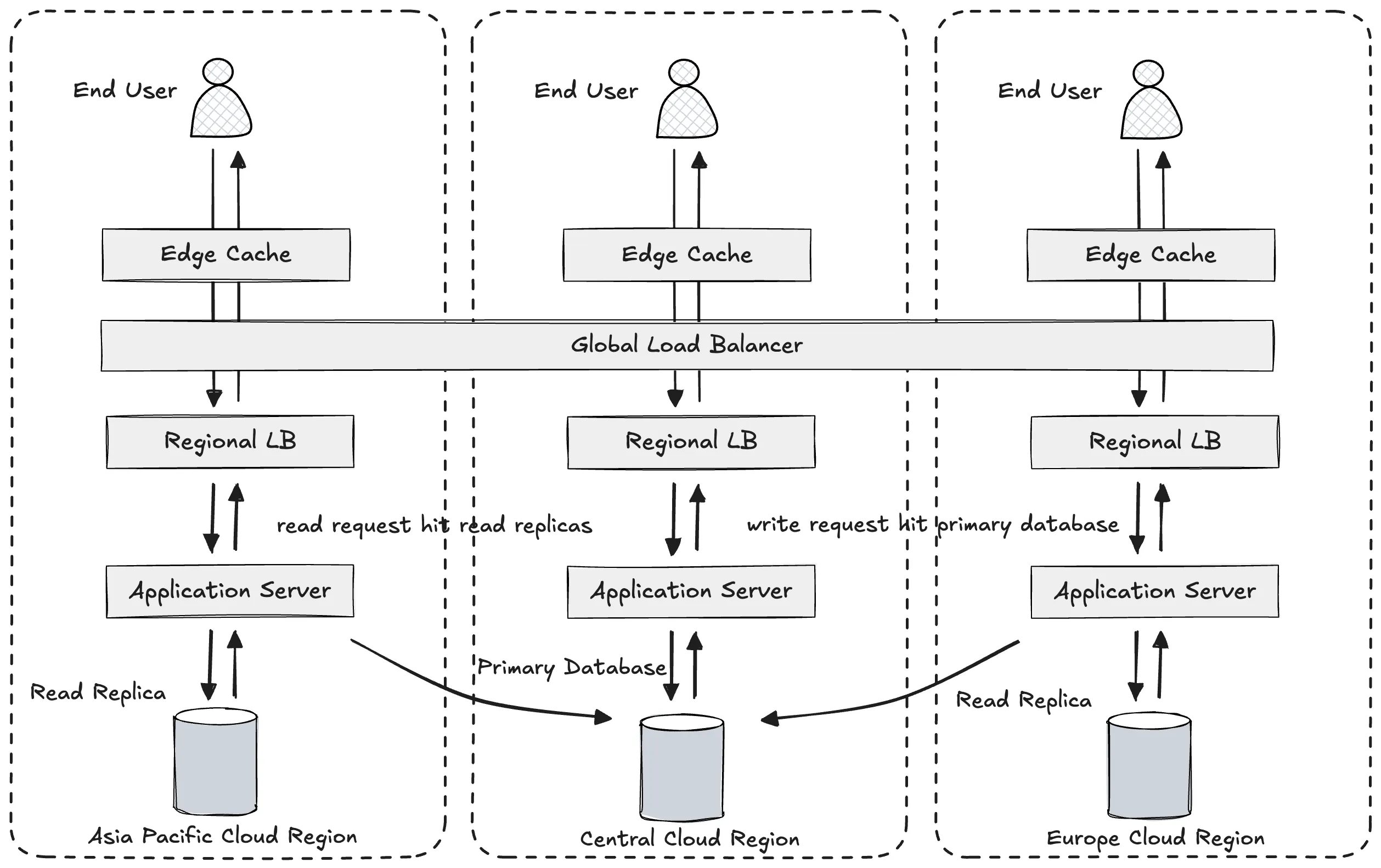
Benefits of Read Replicas in a Global Service
-
Reduced Latency for Read Operations
When users in Europe, North America, or South America query the game for their card decks, match history, or in-game store data, their requests are directed to local read replicas instead of traversing the globe to the Asia-Pacific main region. This drastically reduces round-trip times, creating a snappier, more responsive user experience. -
Global Load Balancing for the Database Tier
Instead of burdening a single primary database with all read and write traffic, read replicas distribute the read load across regions. This leads to higher throughput, better fault tolerance, and a more scalable architecture. -
Disaster Recovery and Redundancy
Read replicas serve as an added layer of redundancy. If the primary region suffers an outage (e.g., due to a natural disaster, connectivity loss, or regional failure), these replicas can serve as failover candidates, helping maintain business continuity. -
Cost Efficiency for Read-Heavy Workloads
Most multiplayer games are read-heavy. Player data, leaderboards, match history, and inventory details are read far more frequently than they are updated. Using replicas offloads this burden from the primary database and allows for regionally optimized billing where data egress costs are minimized by serving content locally.
Trade-Off: Asynchronous vs Synchronous Replication
By default, read replicas update asynchronously — meaning they eventually reflect the state of the primary database, but there is a small lag window where recent updates may not be immediately available. This is acceptable for most gameplay scenarios, such as browsing card collections or viewing past matches.
However, in highly consistent environments — like when validating in-game purchases or match results — this lag could introduce inconsistencies. In such cases, synchronous replication can be used to ensure that every replica is fully up-to-date before responding to queries. But this comes at the cost of increased write latency and inter-region coordination overhead.
When Should You Use Read Replicas?
Read replicas are ideal if your application:
- Has global users spread across different geographic regions
- Is read-heavy, where write latency can be slightly decoupled from read requirements
- Can tolerate eventual consistency for most use cases (e.g., dashboards, historical data, user profiles)
- Requires low-latency access to non-critical user data to enhance experience
In the case of our massively multiplayer card game, read replicas make perfect sense for:
- Fetching user profiles
- Viewing marketplace data
- Loading battle history or card stats
- Reading leaderboard scores
However, they may be less suited for operations that require immediate consistency, such as processing battle results or real-time inventory updates — unless carefully engineered with conflict resolution mechanisms or fallback paths.
What’s Next?
Read replicas are just one of several strategies available for multi-region database distribution. In the next section, we’ll dive into database sharding and explore how horizontal partitioning across regions can further enhance scalability, write performance, and fault isolation.
Region-Specific Independent Distributed Databases
As our application scales globally and begins to experience heavy write traffic across multiple regions, we encounter limitations with read-replica models. In these scenarios, simply distributing read replicas is insufficient — because all write operations still funnel back to the primary database, creating latency bottlenecks and increasing the risk of performance degradation.
To address this, one of the most effective strategies is to deploy region-specific independent databases, each serving the write and read requests for its respective geographic location.
Why Independent Regional Databases?
In contrast to a central write-dominant architecture or a read-optimized replica setup, independent regional databases offer several critical advantages:
-
Low Latency for Writes
Players in North America, Europe, or Southeast Asia can write directly to their local databases without routing traffic through the primary cloud region. This removes the latency introduced by cross-region network hops, significantly enhancing performance during high-frequency game interactions — such as card trades, battles, and marketplace transactions. -
Workload Isolation and Scalability
Each region’s database can be independently scaled based on its local demand. If Europe sees a spike in new players due to a regional promotion, the infrastructure in that region alone can be expanded without impacting other zones. This decouples performance between regions and ensures localized fault containment. -
Compliance with Data Residency Laws
Many countries now enforce strict data sovereignty laws, requiring that user data generated within a region must remain in that region. This is especially relevant for platforms operating in the EU, China, India, or Brazil. Independent regional databases make it feasible to adhere to these regulations without compromising architectural integrity.
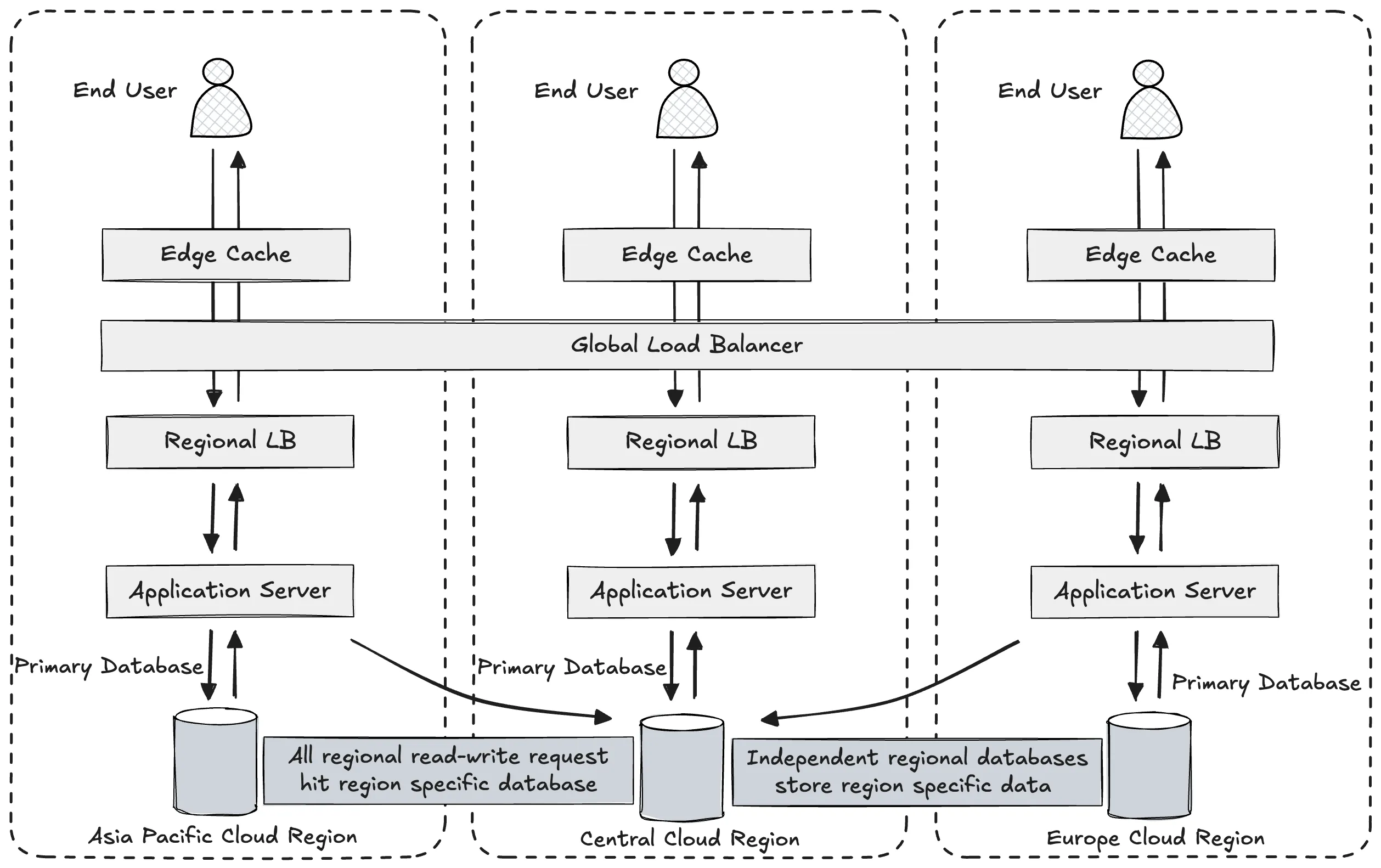
Limitations and Trade-Offs
While regional independence offers performance and regulatory advantages, it also introduces architectural complexity — especially in global state synchronization.
Let’s say your game tracks global leaderboards, cross-region matchups, or shared inventories for tournament play. In such use cases:
- You’ll need to synchronize writes across regional databases to maintain a consistent global state.
- These writes cannot happen in real time without introducing global locking or coordination overhead, so the model defaults to eventual consistency.
- For latency-sensitive applications or highly coupled game mechanics, this may lead to data conflicts or delayed visibility, which must be handled gracefully in the application logic.
In effect, you’re balancing local autonomy with global coherence.
Example Scenarios in a Gaming Context
-
A player in Japan completes a high-stakes battle and ranks among the top 100 globally. The write occurs in the Tokyo database, but this rank update needs to propagate asynchronously to the global leaderboard service that aggregates data from all regions.
-
During cross-regional tournaments, players from different parts of the world must be matched in near real time. This necessitates a global matchmaking layer that understands the distributed nature of regional data and can coordinate outcomes effectively.
-
If your game supports global marketplaces (e.g., card exchanges across regions), then ensuring inventory synchronization becomes crucial. This may involve streaming event logs (e.g., via Kafka or pub/sub systems) from regional databases to a central processing service.
Key Takeaways
-
When to use: Region-specific databases are ideal when your application sees high write volume across regions and cannot afford to centralize writes without impacting user experience.
-
What to watch for: With decentralized write systems, you must handle eventual consistency, conflict resolution, and global synchronization with care.
-
Best practices:
- Use event-driven replication pipelines to propagate global state.
- Maintain idempotent operations for reprocessing events without side effects.
- Implement application-level versioning or timestamp-based reconciliation to resolve conflicts across writes.
- Where strong consistency is essential (e.g., financial transactions), consider using a dedicated global coordination layer or hybrid approaches.
Independent, region-specific databases offer a powerful architecture for handling global write-heavy workloads while ensuring compliance and performance. However, this approach is not plug-and-play. It requires careful planning, sophisticated synchronization strategies, and an understanding that perfect global consistency may not always be achievable — or even necessary — depending on your app’s business logic.
As the architecture of your system evolves, striking the right balance between local responsiveness and global consistency is key to delivering an immersive and scalable multiplayer experience.
Synchronizing Data Across Global Nodes of a Distributed Database
Designing distributed systems that span the globe is no small feat, and at the heart of this complexity lies one of the most formidable challenges in modern systems architecture: synchronizing data writes across globally distributed nodes. While read operations can often be served locally or through replicas with minimal friction, coordinating writes across regions—where latency, consistency, and availability intersect—is where the true engineering depth is required.
The Complexity of Global Synchronization
At first glance, deploying a database node in each region seems like a practical solution to minimize latency for local users. However, the real challenge emerges when these nodes need to reflect a consistent global state—especially when users across different regions are concurrently modifying shared resources.
This is not just about replication or syncing data at intervals. It’s about ensuring consistency across a dynamic, ever-changing dataset, in real time or near-real time, despite unpredictable network conditions, varying latency, and potential node failures.
Here’s what complicates global synchronization:
- Latency Tolerance: Some applications (e.g., gaming or finance) require updates in milliseconds. Waiting for a consensus from nodes across continents can slow performance.
- Network Partitioning: In distributed systems, partial failures (where some nodes can’t communicate) are common. The system must gracefully handle these scenarios without corrupting state.
- Availability Expectations: Services like multiplayer games or global collaboration tools can’t afford to be offline, even during sync delays.
- Consistency Requirements: Do all users need to see the same version of the data immediately? Or is eventual consistency acceptable for your use case?
These concerns must be balanced using distributed systems theory and real-world architecture trade-offs.
Techniques Used in Distributed Databases
To address these challenges, modern distributed databases and platforms use a mix of the following strategies:
Quorum-Based Consistency
Databases like Apache Cassandra and Amazon DynamoDB use quorum-based approaches to balance consistency and availability. In this model:
- A write must be acknowledged by a minimum number of nodes (a write quorum).
- Reads are also served from a quorum of replicas to ensure the latest data is returned.
This approach offers tunable consistency—developers can configure how many replicas must agree for a read or write to succeed.
Consensus Algorithms (Raft, Paxos, etc.)
When strong consistency is required, systems employ consensus protocols. These ensure that distributed nodes agree on the order of operations, even if some nodes fail.
- Raft (used in etcd, CockroachDB) and Paxos (used in Google’s Chubby lock service) are the most common protocols.
- These protocols elect a leader node to coordinate updates, then propagate changes in a strictly ordered fashion.
While powerful, consensus-based systems can introduce latency—particularly in high-latency WAN environments—so they’re typically reserved for operations requiring absolute consistency.
Vector Clocks and Versioning
Some systems handle conflicting writes by maintaining vector clocks—metadata that tracks the causal relationship between different versions of data.
This technique doesn’t resolve conflicts automatically but empowers applications to merge changes intelligently based on business logic (e.g., most recent update, user-preferred input, etc.).
Hybrid Consistency Models
Some modern platforms (like Spanner, YugabyteDB, and FaunaDB) implement multi-model consistency layers—offering strong consistency for core operations and eventual consistency for secondary workloads, such as analytics or logs.
This allows applications to optimize for performance without compromising on integrity where it matters most.
Engineering for the Real World
In a real-world distributed architecture—such as a globally popular card game or collaborative SaaS tool—the choice of synchronization strategy is never binary. It must reflect the application’s needs:
- Does your leaderboard require global truth, or can it be eventually consistent?
- Is it acceptable for two players to temporarily see different game states?
- Do you need to reconcile product inventory changes across regions in real time?
These are not just technical questions—they’re product and user experience decisions that inform architectural design.
Looking Ahead
This topic is vast and rich with nuance. From database growth strategies and consensus algorithms to multi-region deployment patterns and event stream reconciliation—there’s a deep well of knowledge every software architect must tap into.
If you’re ready to explore the full depth of distributed systems design, from foundational principles to advanced scenarios inspired by the architectures of Netflix, YouTube, or ESPN, consider diving into the Zero to Software Architecture Proficiency learning path.
This comprehensive course series is authored by engineers who’ve built globally scalable services and covers:
- Data modeling in distributed databases
- Distributed transaction handling
- Eventual vs. strong consistency trade-offs
- Conflict resolution mechanisms
- Global cloud deployment patterns
- And much more…
Synchronizing data across global nodes isn’t just a technical optimization—it’s an architectural decision that shapes the reliability, performance, and integrity of your distributed system. Whether you’re designing the backend for a high-stakes game, a multinational marketplace, or a real-time analytics engine, understanding the synchronization mechanics and the trade-offs involved is paramount to your success.
Hybrid Distributed Database Architecture: Combining Read Replicas and Active-Active Regional Deployments
Running distributed systems at a global scale is never straightforward. While theory often nudges architects toward idealized blueprints—whether eventual consistency or strong guarantees—the reality of global applications is far more nuanced. The truth is: there’s no one-size-fits-all architecture. What emerges instead is a hybrid approach, molded by regional regulations, user expectations, data residency requirements, and the nature of application traffic.
When building something like a massively multiplayer online (MMO) game, where latency, reliability, and regional customization are paramount, a hybrid distributed database architecture often becomes not just a best practice—but a necessity.
Understanding the Need for a Hybrid Model
Imagine operating a game that spans dozens of countries, each with its own set of rules, languages, data laws, and usage patterns:
- In some regions, regulations require that user data must remain local, making cloud-region-specific deployments with dedicated databases essential.
- In others, you may have legal limitations on feature availability, such as in-app purchases or PvP interactions, meaning only read operations are permitted.
- Certain zones might simply act as read-heavy clusters, sending users to local read replicas to minimize latency without requiring full write access.
- Simultaneously, core game logic and leaderboard operations may need active-active databases to synchronize and resolve user progression across multiple geographies.
Enter the hybrid architecture—a strategic fusion of read replicas and independent regional deployments.
Architecture Overview: The Best of Both Worlds
Here’s how a hybrid architecture might be designed for our MMO game platform:
- Global Load Balancer: Routes users to the closest cloud region based on latency, availability, and failover logic.
- Read Replicas in Low-Write Regions: Deployed in regions where users can access content but are restricted from actions that generate new writes (due to legal or feature-based constraints). These read replicas are asynchronously synced from the primary or regional active database clusters.
- Active-Active Regional Databases: Deployed in regions where full read-write access is needed. These clusters handle localized data persistence and may use distributed consensus or event-based synchronization to communicate critical state back to the core game database.
- Policy-Based Routing and Feature Flagging: Used to disable or reroute write-enabled features in regions where full databases aren’t deployed or where data sovereignty limits functionality.
This flexible model allows architects to meet regulatory compliance, enhance performance, and reduce complexity, all while giving teams granular control over where and how data flows.
Benefits of a Hybrid Architecture
- Regulatory Compliance: By deploying region-specific active databases, your system respects local data residency laws and privacy mandates—essential for GDPR, India’s PDP Bill, and similar global legislation.
- Optimized Latency: Regional read replicas serve static or cacheable content fast, minimizing round-trip latency to distant cloud regions.
- Simplicity in Sync Zones: Reduces the burden of full cross-region write synchronization by isolating where writes occur and where only reads are allowed.
- Cost Control: Not every region needs full database clusters. By combining read replicas with active deployments only where necessary, resource usage can be optimized without sacrificing user experience.
- Flexible Scalability: Regions with growing engagement can be upgraded from replica-only to full write-enabled clusters without overhauling the core architecture.
Challenges to Address
However, this hybrid model is not without trade-offs:
- Data Consistency and Synchronization: If certain gameplay events span across regions (like global tournaments or cross-border leaderboards), systems must handle eventual consistency gracefully and detect anomalies or out-of-sync states.
- Operational Overhead: Managing multiple types of database deployments increases the complexity of monitoring, failover design, and backup policies.
- Migration and Evolution: As certain regions grow in user base or legal structures change, you may need to transition a read-replica region to a full active deployment—requiring robust tooling and CI/CD pipelines.
When to Choose a Hybrid Model
You should consider implementing a hybrid architecture when:
- You operate in multiple jurisdictions with varied data residency requirements.
- Your application exhibits uneven read/write patterns across regions.
- You need to balance latency, compliance, and cost-efficiency.
- Your app has globally distributed user bases but features that are regionally distinct (e.g., matchmaking policies, payment systems).
In the world of distributed databases, flexibility is power. A hybrid architecture that blends read replicas for latency optimization with region-specific independent deployments for legal and performance demands offers organizations a highly adaptable path forward.
It’s not always easy—but it’s necessary for building robust, user-friendly, and globally compliant applications at scale. As your service footprint expands, this architecture lets you grow with confidence, knowing your database strategy is as dynamic and resilient as your users expect your app to be.
Globally Sharding Your Database Across Cloud Regions
So far, we’ve explored two common approaches for scaling databases across multiple regions: deploying read replicas to reduce latency and distributing independent databases regionally to handle localized writes. Both approaches offer unique advantages depending on traffic patterns, regulatory requirements, and system design constraints.
But there’s another powerful strategy worth considering—database sharding. Sharding allows us to horizontally partition a large database into smaller, more manageable pieces, known as shards, and distribute these shards across various cloud regions.
What Is Database Sharding, and Why Does It Matter?
Sharding is a technique that splits a monolithic database into smaller, distinct segments, each responsible for a subset of the data. These segments, or shards, can be hosted across multiple cloud regions. This not only improves scalability and performance, but also reduces latency by placing data closer to where it’s most frequently accessed.
Unlike region-specific independent deployments—which maintain separate full databases with their own application logic and data—shards function as part of a larger, unified database system. Each shard contains a logically partitioned slice of the data, determined by a sharding key such as:
- Geographic location (e.g., North America users vs. Europe users)
- User attributes (e.g., user ID ranges or segments based on user tiers)
- Feature participation (e.g., players active in PvP mode vs. those who only collect cards)
Architecture Overview: Shards as Logical Segments in a Unified Database
Let’s visualize how this works in a globally distributed game architecture.
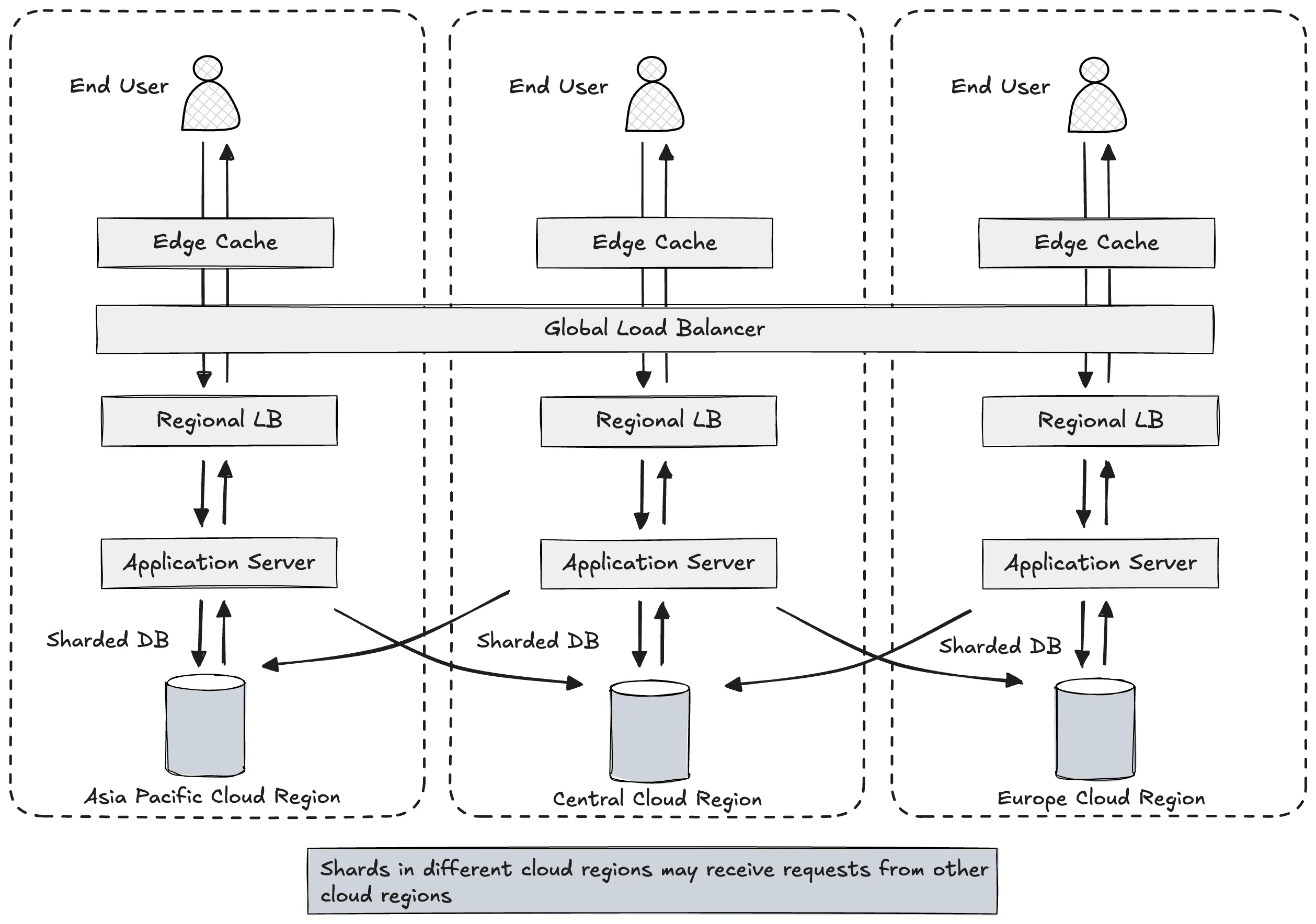
In this model:
- Each shard is placed in a separate cloud region, optimized for a particular slice of users or data.
- Requests are routed to the appropriate shard based on the sharding logic configured within the application layer or routing middleware.
- Shards can still be queried globally, but each one is optimized to handle a specific portion of the load.
- The system, as a whole, behaves like a single, distributed database, where each shard collaborates with others under centralized control.
Key Benefits of Global Sharding
Performance Optimization: By routing traffic only to relevant shards, overall system response times drop dramatically. Users don’t wait for monolithic databases to process irrelevant data.
Improved Fault Isolation: A failure or slowdown in one shard only affects the subset of users associated with that shard, rather than the entire global user base.
Scalability: Need to support more players in South America? Spin up a new shard dedicated to that region without overloading existing infrastructure.
Cost Efficiency: Each shard can be independently scaled up or down, helping control costs based on demand in each region.
How Sharding Differs from Independent Regional Deployments
It’s important to differentiate shards from region-specific independent databases:
| Feature | Shards | Independent Regional Databases |
|---|---|---|
| Data Relationship | Part of a unified system | Self-contained per region |
| Write Capability | Configurable (global or localized) | Local writes only |
| Data Routing | Based on sharding key logic | Based on region-specific deployment |
| Cross-Region Sync | Not required unless data overlaps | Optional, usually for leaderboards or compliance |
| Example Use | Store user segments based on IDs | Store regionally regulated data |
While regional databases are often used to satisfy compliance or localized performance, sharding focuses on performance through segmentation, and is often best for large-scale, high-traffic global applications with dynamic usage patterns.
Considerations for Designing a Sharded Global System
Of course, sharding isn’t without challenges:
- Smart Sharding Key Selection: Poor key design can lead to hotspots, where one shard is overloaded while others are underutilized.
- Shard Rebalancing: As usage patterns evolve, some shards may grow disproportionately, requiring data migration or rebalancing strategies.
- Operational Overhead: Managing consistency, routing logic, monitoring, and failover across multiple shards can add significant complexity.
That said, many modern databases like CockroachDB, YugabyteDB, MongoDB, and platforms like Google Spanner offer built-in sharding support that handles much of this complexity under the hood.
When to Use Sharding in a Multi-Region Architecture
Global sharding becomes a preferred choice when:
- You have millions of concurrent users spread across geographies.
- Your system experiences heavy concurrent write and read workloads.
- You require low-latency access for specific user segments.
- You’re anticipating hypergrowth and want infrastructure that scales horizontally with user base expansion.
Sharding your database across multiple cloud regions introduces a high degree of flexibility, performance tuning, and fault tolerance. When done right, it enables your platform to support massive concurrent workloads, while keeping latency low and user experience responsive—even under peak demand.
In the context of a global MMO card game, this means faster matchmaking, seamless card trading, and consistent player experiences regardless of geography.
Choosing the Optimal Database Distribution Strategy for Global Applications
Designing a globally distributed application—especially one serving real-time users like a massively multiplayer online game—requires careful selection of the database architecture that underpins the entire system. Whether the application is read-heavy, write-intensive, subject to strict data sovereignty laws, or needs to ensure sub-100ms response times across geographies, the database strategy you choose will determine the scalability, resilience, and performance of your service.
When evaluating how to architect your backend data infrastructure across cloud regions, there are three foundational patterns to consider:
- Read Replicas
- Cloud Region-Specific Independent Deployments
- Globally Sharded Databases
And in many modern applications, a hybrid approach—combining two or all three of these strategies—is often the most effective.
Evaluating the Right Fit: Key Considerations
Before diving into one pattern or another, your architecture should be guided by a deep understanding of your business and technical requirements. Here are some of the most important factors to evaluate:
- Traffic Patterns: Are user requests predominantly reads, writes, or a balance of both? Where do your users live?
- Consistency Requirements: Is eventual consistency acceptable, or do you need strong guarantees?
- Latency Tolerance: What response time is acceptable for the core user experience?
- Regulatory Compliance: Do local laws mandate data residency within certain jurisdictions?
- Operational Complexity and Cost: How much infrastructure and overhead are you prepared to manage?
When to Use Read Replicas
If your application experiences globally distributed read-heavy traffic, and write operations aren’t overly sensitive to latency or strict consistency, then read replicas are a simple yet powerful option.
Read replicas:
- Offload read traffic from the primary database
- Improve latency for users in remote regions by serving localized data
- Act as natural backups and improve disaster recovery capabilities
However, they come with a trade-off—eventual consistency. Replicas are updated asynchronously from the primary, which introduces potential delays in data propagation.
Best for: FAQs, content retrieval, user dashboards, cached player stats, read-only experiences.
When to Deploy Independent Region-Specific Databases
If your service needs to comply with local data residency laws, or you’re handling latency-sensitive write traffic, you’ll need to push full database deployments closer to where the data is generated.
Independent databases allow you to:
- Meet regional compliance and legal constraints
- Reduce write latency for transactional workloads
- Scale infrastructure independently based on regional demand
However, this approach introduces challenges with synchronization. If you need global consistency—say for worldwide leaderboards or game states—you’ll need to engineer cross-region data replication, conflict resolution, and reconciliation logic.
Best for: Regulatory compliance, regional leaderboards, game matchmaking, localized data sovereignty.
When to Use Global Sharding
Global sharding is ideal when your system is expected to handle high concurrency, scalable traffic, and when you want a single logical database that’s optimized by geographic or behavioral partitioning.
With a sharded architecture, your data is distributed across regions, but remains part of one coordinated system. This offers:
- Ultra-low latency by placing data near its most frequent access point
- Flexible routing logic that scales horizontally
- Logical grouping by geography, user segment, or feature usage
It does, however, require sophisticated orchestration, including sharding key selection, metadata tracking, and global routing control.
Best for: High-scale platforms, real-time analytics, global multiplayer services, usage-tiered segmentation.
When to Consider a Hybrid Strategy
In the real world, one size rarely fits all. As services grow, their use cases evolve, and regional demands fluctuate, a hybrid database architecture can be the best way to balance performance, complexity, and cost.
Examples of hybrid scenarios include:
- Sharded databases for game state and user profiles
- Read replicas for frequently accessed leaderboards or historical stats
- Independent deployments in countries requiring in-region data control
This mix allows engineering teams to apply the right level of optimization to each region and data type, maximizing efficiency while maintaining agility.
What About Serverless Managed Databases?
As an emerging trend, serverless managed databases are gaining traction—particularly for applications that need to scale rapidly while minimizing operational overhead.
These services:
- Handle infrastructure provisioning and auto-scaling
- Manage connection pooling (critical for high concurrency)
- Provide APIs for direct integration with modern frontend frameworks and thick clients
Platforms like Firebase, PlanetScale, Neon, and Supabase are offering increasingly mature options for global apps. These solutions are particularly useful when building modern web or mobile apps that need real-time sync, offline support, or API-driven data access.
There is no universally perfect database architecture—but there is a perfect fit for your unique use case.
Whether you’re optimizing for performance, compliance, developer velocity, or cost, your architecture should be guided by user behavior, business goals, and system constraints.
For a rapidly scaling multiplayer game—or any globally distributed service—the right database strategy can be the difference between a laggy, frustrating experience and a responsive, engaging platform that users love.
Understanding the Inevitable Trade-offs in System Architecture
Designing a robust and scalable global system—especially one that demands real-time interactivity like an online multiplayer card game—is a balancing act. Every architectural decision comes with its own set of trade-offs, and understanding those trade-offs is what separates a functional system from an exceptional one.
Let’s walk through a practical, high-stakes scenario to illustrate this:
Scenario: Battle Royale Mode Across Multiple Cloud Regions
Imagine our popular card-based battle royale game has taken off, and we’re now live in four global cloud regions. Players from across the globe are entering competitive matches, dueling in real-time, and participating in a constantly updating leaderboard that reflects in-game performance across all regions.
Now, real-time interaction is absolutely critical for game mechanics—every card play, attack, or counter must be registered with near-zero latency to maintain a seamless and fair gameplay experience. To achieve this, we instinctively move to deploy region-specific databases, bringing data closer to the users and cutting round-trip latency down to milliseconds.
Enter the Global Leaderboard: A System-Wide Consistency Requirement
But here’s the catch: we also want to offer a live global leaderboard—a feature that showcases top players from every region, updating instantly as games conclude. This isn’t just a nice-to-have; it’s a core motivational mechanic for our players. To ensure this leaderboard reflects real-time accurate rankings, we now need strong consistency across the entire system. That means every write operation (like updating match results) must be reflected across all regions immediately and reliably.
The Conflict: Latency vs. Consistency
We’ve now hit the architectural equivalent of a fork in the road:
- If we spread writes across all cloud regions to reduce latency, we introduce eventual consistency, risking delayed or incorrect global rankings.
- If we centralize writes to ensure strong consistency, we increase latency for users far from the write region, potentially degrading the in-game experience.
This is a textbook example of the CAP theorem in action—where Consistency, Availability, and Partition tolerance cannot all be fully achieved simultaneously. In our case, we’re forced to trade off between latency and consistency.
Designing around this challenge might include strategies such as:
- Employing leader-follower models with priority regions handling consistency-sensitive writes
- Utilizing conflict-free replicated data types (CRDTs) to merge concurrent changes
- Introducing tiered data propagation to segment what needs strong consistency vs. what can tolerate eventual consistency
- Leveraging quorum-based writes across prioritized zones
The Takeaway: Every Decision Has a Cost
This example underscores a fundamental truth in architecture: there is no one-size-fits-all solution. Every decision you make will optimize for some things and compromise on others.
Want lower latency? You might compromise on global consistency. Need strong consistency? You may have to accept higher latency or reduced availability. Prioritize simplicity? You might be leaving performance on the table.
And here’s the kicker: Designing distributed systems is not just about knowing what’s possible—it’s about understanding what you’re willing to trade off, and when.
Conclusion: The Art and Architecture of Global Scalability
In the ever-evolving world of distributed systems, building globally available, low-latency, and resilient services is not merely a technical challenge—it’s an exercise in architectural foresight, strategic trade-offs, and relentless iteration.
As we’ve explored through the lens of our online multiplayer card game, expanding a service beyond a single cloud region introduces a rich tapestry of complexities. From choosing between read replicas, region-specific deployments, or sharded databases, to synchronizing data across disparate zones, and managing competing demands for latency, consistency, and compliance—each decision layers on operational consequences that ripple across your stack and your user experience.
There is no silver bullet. There is no perfect architecture. What exists is a continuum of trade-offs that must be balanced according to business needs, player experience, technical constraints, and regulatory boundaries.
Whether it’s maintaining global leaderboards in real time, or ensuring that customer data adheres to regional laws, the modern architect must wear many hats: part systems engineer, part strategist, part futurist.
The key takeaway? Architectural excellence lies not in finding the ideal solution—but in choosing the right compromise.
As you scale your services, always come back to the core principles:
- Where is your user?
- What experience do they expect?
- What does your data need to guarantee—consistency, locality, durability?
- Where are you willing to bend—latency, complexity, or cost?
Ultimately, your architecture should tell the story of your product’s promise—fast, responsive, and reliable to the player no matter where in the world they connect from.


