
In the ever-expanding world of AI applications, redundant API calls and repeated computation pose a serious bottleneck to performance and cost-efficiency. Enter semantic caching—an AI-native approach to caching that understands the meaning of a query rather than relying on exact string matches.
In this post, we’ll break down a working Python implementation of a semantic cache using OpenAI (or FastEmbed) and the Qdrant vector store. This project is minimal, intuitive, and ready for LLM workflows. This is purely for basic understanding and function of a semantic cache and it’s components.
What Exactly is a Semantic Cache?
At its core, a semantic cache is a smarter, AI-native alternative to traditional key-value caches. Whereas standard caches depend on exact string matches (e.g., the same API call or query text), a semantic cache relies on meaning and context—even when the wording changes.
This is achieved by using text embeddings, which convert text into high-dimensional vectors that capture the semantic essence of the input. These vectors are not just hashes—they’re mathematical representations of meaning.
Let’s walk through the process step-by-step:
Semantic Caching Flow in Detail
Query Encoding into Embedding Space
When a user submits a prompt—say:
“What’s the capital of France?”
The system doesn’t simply store that string. Instead, it feeds the prompt into an embedding model like OpenAI’s text-embedding-ada-002 or FastEmbed. The model converts the text into a dense vector—a list of numbers in a high-dimensional space (typically 384–1536 dimensions).
This vector captures the meaning of the sentence, regardless of its exact phrasing.
Semantic Lookup via Vector Similarity
Next, the system uses a vector database—in this case, Qdrant—to search for previously stored vectors that are close to the new vector in the embedding space. This is done using cosine similarity, dot product, or other distance metrics.
For example:
- If “What’s the capital of France?” is semantically close to “Name the main city in France”, they’ll be nearby in vector space.
- The cache doesn’t care if the wording differs—as long as the intent and meaning are similar.
Threshold-Based Cache Hit Decision
To determine if a retrieved match is “good enough,” a similarity threshold is used (e.g., 0.9 cosine similarity). If a result is found and its similarity score exceeds the threshold, it is considered a cache hit. The system then returns the stored response immediately—without calling the LLM.
This delivers blazing-fast responses, saves tokens, and reduces compute/API costs.
Fallback to LLM and Cache Write
If no sufficiently close match is found, the cache forwards the prompt to the LLM (e.g., GPT-4 or Claude). Once a fresh response is generated:
- The prompt is embedded
- The vector and response are stored in Qdrant for future reuse
This ensures that the cache learns continuously—adapting to new questions and user styles over time.
Semantic caching adds cognitive efficiency to your applications:
- Handles paraphrased or reworded queries gracefully
- Minimizes unnecessary LLM invocations
- Serves as a persistent, evolving memory layer
- Cuts down on inference/API costs
- Enables higher responsiveness in chatbots, agents, and search tools
It is especially powerful in scenarios involving retrieval-augmented generation (RAG), AI agents, search systems, or interactive chat interfaces—where user prompts are often repeated or varied only slightly.
Architecture Overview
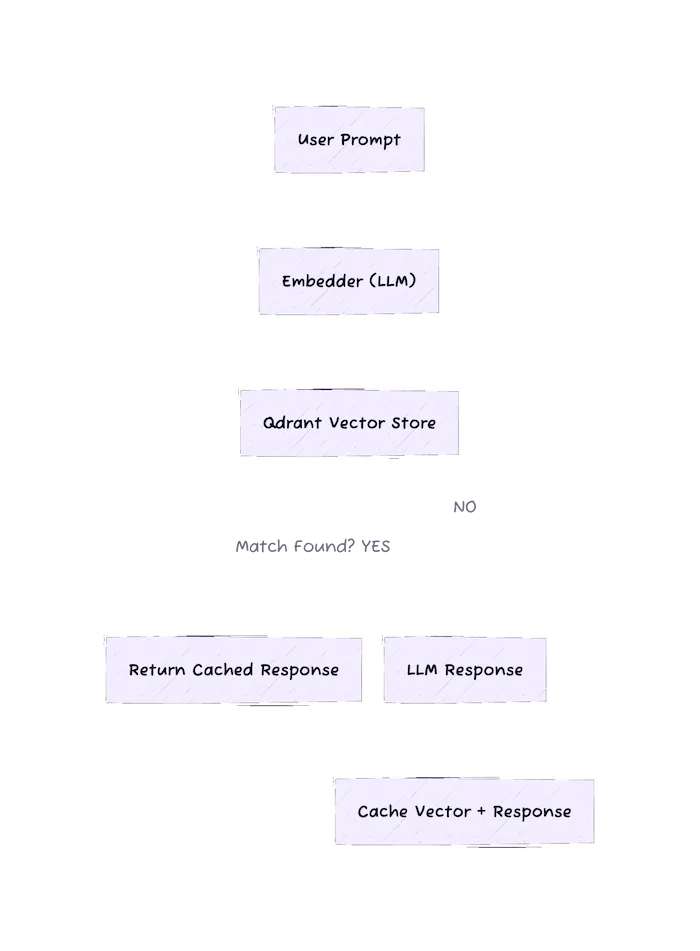
Architectural Flow: Semantic Cache System
The architecture illustrates the life cycle of a user query as it passes through a semantic cache layer before reaching an LLM. This system is designed to optimize performance, reduce redundant calls to large language models, and improve the responsiveness of intelligent applications.
User Prompt Input
The flow begins when a user submits a natural language query—this could be a message in a chatbot, a question in a virtual assistant, or a prompt within an AI workflow.
Embedder (LLM)
Instead of processing the text directly, the system sends the prompt to an embedding model, which transforms it into a high-dimensional vector. This vector representation captures the semantic meaning of the prompt and is crucial for identifying similarity rather than relying on literal text.
This component can be powered by:
- OpenAI’s embedding models (e.g.,
text-embedding-ada-002) - FastEmbed for local, high-speed embedding
- Any SentenceTransformer model (like
all-MiniLM-L6-v2)
Qdrant Vector Store
The resulting vector is then sent to a Qdrant vector database, a high-performance similarity search engine built for dense embeddings. Qdrant compares the new query vector to stored vectors representing past user queries and their corresponding responses.
Cache Hit?
- If a close match is found (based on cosine similarity and a configurable threshold, e.g., ≥ 0.9), the system determines that the new query is semantically similar to a previous one.
- It returns the cached response, skipping the need to call the LLM again. This significantly reduces cost and latency, especially in high-frequency environments.
No Match Found
- If no match is sufficiently close, the system falls back to the LLM, sending the original prompt for processing.
- The LLM generates a fresh response, just like it would in a traditional pipeline.
Cache Update
Finally, the system stores the new query-response pair by embedding the prompt and inserting it along with the response into the Qdrant vector store. This way, future queries with similar intent can be handled more efficiently.
Code Highlights
Setup and Dependencies
Install the required libraries:
pip install qdrant-client openai python-dotenv# Optional for FastEmbed versionpip install fastembedCreate a .env file from env.example with:
OPENAI_API_KEY=your-keyQDRANT_HOST=localhostQDRANT_PORT=6333Embedding and Search Logic (llmcache.py)
from openai import OpenAIEmbeddingsfrom qdrant_client import QdrantClient
def embed_text(text): response = openai.Embedding.create( input=[text], model="text-embedding-ada-002" ) return response["data"][0]["embedding"]Search in Qdrant
client = QdrantClient(host="localhost", port=6333)
hits = client.search( collection_name="semantic-cache", query_vector=embed_text(prompt), top=1, score_threshold=0.9 # cosine similarity)
if hits: print("Cache HIT:", hits[0].payload['response'])else: # Call LLM and store resultCaching New Responses
client.upsert( collection_name="semantic-cache", points=[{ "id": uuid.uuid4(), "vector": embed_text(prompt), "payload": {"prompt": prompt, "response": llm_response} }])FastEmbed Alternative (llmfastembedcache.py)
FastEmbed is a blazing-fast open alternative for generating embeddings locally:
from fastembed.embedding import OnnxEmbeddingModel
embedder = OnnxEmbeddingModel(model_name="all-MiniLM-L6-v2")vector = embedder.embed_query(prompt)This removes dependency on OpenAI and keeps embedding computation fully local.
Running the System
To try it out:
- Launch Qdrant:
docker compose up- Run the Python script:
python llmcache.py # for OpenAIpython llmfastembedcache.py # for FastEmbed- Chat in terminal:
You: What's the capital of Germany?Bot: Berlin is the capital of Germany.
You: What's Germany's main city?Cache HIT: Berlin is the capital of Germany.Final Thoughts
This project represents more than just a minimal implementation—it’s a gateway into production-grade AI optimization. By combining modern embedding models with vector search tools like Qdrant, it elegantly demonstrates how developers can build intelligent memory layers that understand not just what the user says, but what they mean.
Whether you’re experimenting with chatbots, agent frameworks, or retrieval-augmented generation (RAG) pipelines, this simple semantic cache shows how to significantly reduce unnecessary API calls, improve latency, and add contextual intelligence to your applications.
Even more impressive is the fact that the core of this system is compact—just a few lines of Python wrapped around a powerful concept. It’s lightweight enough to deploy on the edge, yet extensible enough to integrate into enterprise-grade architectures with advanced caching strategies, TTL, hybrid scoring, and persistent storage.
This implementation proves that AI memory systems don’t have to be complex to be powerful. With clear modular components and plug-and-play extensibility (OpenAI → FastEmbed, in-memory → Qdrant), it’s a brilliant foundation for anyone serious about building responsive, cost-effective, and intelligent AI systems.
👉 Explore it further on GitHub:
https://github.com/TechcodexIO/simple-semantic-cache


