
Understanding Distributed Systems: Layers and Applications Across the Compute Stack
Distributed systems are not a singular technology or product — they are a design philosophy, a structural approach, and a foundational necessity in the architecture of modern digital services. When people hear the term “distributed system,” they often think of high-profile tech giants like Uber, Netflix, and YouTube. These companies exemplify distributed systems at scale — orchestrating millions of user interactions, data exchanges, and compute cycles across global networks. But to truly understand what makes a system “distributed,” we must look deeper — across the layers of the compute stack that bring these services to life.
At its core, a distributed system is a collection of independent components — typically running on different physical or virtual machines — that communicate and coordinate with each other to appear as a single cohesive system to the end user. This coordination can span the compute stack: from infrastructure and networking layers, to data storage, to application logic, all the way to user-facing APIs.
At the lowest layers, infrastructure and networking ensure that nodes — whether they be physical servers, containers, or virtual machines — can communicate reliably, securely, and with minimal latency. Technologies like service meshes, load balancers, and DNS routing come into play here, creating the highway system that data and requests travel across.
Moving up the stack, storage systems and databases introduce their own complexities. Distributing data across nodes introduces the famous CAP theorem trade-offs — consistency, availability, and partition tolerance. This layer is responsible for not just storing data, but ensuring it’s accessible and coherent across geographies. Distributed databases, object stores, and caching layers operate in concert to achieve this.
At the application and services layer, microservices are often the architectural unit of choice. These independent services can scale horizontally, fail independently, and evolve autonomously. Together, they create a distributed application fabric that can be updated, monitored, and maintained with agility. This layer also includes the orchestration engines (like Kubernetes) and service discovery systems that manage how services find and talk to one another.
Finally, API gateways and client-facing endpoints expose the power of the distributed system to consumers — both internal and external. They ensure that clients interact with a unified interface, regardless of the backend complexity. Whether it’s booking a ride, streaming a movie, or uploading a video, the user perceives a seamless experience powered by layers of distributed compute beneath the surface.
Understanding distributed systems requires an appreciation of how these layers interlock — and how failure, latency, scale, and security must be handled differently at each one. The resilience of a system like Netflix or Uber is not simply the result of robust code — it’s the product of thoughtful architectural choices, rigorous testing, layered redundancies, and an intentional strategy to harness distribution as both a challenge and a strength.
In a world where uptime is measured in milliseconds and user expectations grow daily, distributed systems are no longer a niche consideration — they are the backbone of everything we touch, stream, ride, buy, and share.
What Makes Distributed Systems Essential?
The significance of distributed systems becomes most apparent when you consider the scale and demands of modern digital services. Platforms like Uber, YouTube, and Netflix are not just popular applications — they are global-scale ecosystems that must serve millions of concurrent users, process massive volumes of data in real time, and maintain high availability across regions, devices, and networks.
To meet these demands, such platforms rely heavily on a robust ecosystem of distributed technologies. Foundational systems like Apache Kafka, Redis, MongoDB, and Cassandra are more than tools — they are the backbone of real-time data streaming, rapid caching, distributed storage, and horizontally scalable databases. These technologies enable services to break down monolithic constraints and instead operate with loosely coupled components, each optimized for specific workloads and deployed across cloud regions around the world.
Kafka, for instance, serves as a distributed event streaming platform that decouples producers and consumers, enabling real-time ingestion and analytics of high-volume data flows — crucial for use cases like live location tracking or dynamic content recommendations. Redis delivers ultra-low-latency caching, empowering applications to deliver instant responses even under massive load. Databases like MongoDB and Cassandra provide flexible schema design and geographically distributed replicas, ensuring both data locality and global accessibility.
These distributed systems allow services to scale not just vertically (by adding more power to a single node), but horizontally — by adding more nodes, services, and regions without compromising performance. This horizontal scaling is what enables Uber to coordinate millions of rides in real time, or YouTube to deliver video content globally with minimal buffering and high reliability.
In essence, distributed systems are essential not just because they handle scale — but because they enable resilience, elasticity, and global presence. They transform localized infrastructure into globally aware platforms. Without them, achieving the reliability and performance that users expect from modern applications would be impossible.
Ultimately, distributed systems are not just a backend engineering choice — they are a strategic enabler of modern business models, user experiences, and innovation at scale.
Different Facets of “Distributed”
The word “distributed” is deceptively simple, yet it encapsulates a vast and layered architecture that defines how modern digital systems are built and operated. To fully appreciate the depth of this term, it’s important to understand that “distributed” applies at multiple layers within the computing stack — each with its own purpose and implementation.
At the infrastructure level, technologies like Apache Kafka and Redis are referred to as distributed systems because they are architected to operate across large clusters of nodes — sometimes numbering in the thousands. These nodes are often geographically dispersed across cloud regions and availability zones, allowing the system to maintain high availability, scalability, and fault tolerance. When one node fails, others continue to serve the workload without interruption. This redundancy and resilience make it possible to achieve massive throughput and consistent performance, even under extreme load.
For example, Kafka’s distributed design enables it to process billions of events per day, routing and storing messages in real time across multiple producers and consumers. Redis, with its distributed caching model, can serve lightning-fast responses by replicating data across memory instances in various locations, ensuring users always receive the closest and quickest answer.
On the service level, consumer-facing platforms like Netflix, Uber, or Amazon also embody distribution, but in a different context. These services are composed of thousands of microservices — each responsible for a specific capability such as authentication, recommendation, payments, or notifications. These microservices are deployed globally and designed to communicate with one another over lightweight APIs. Despite being physically and functionally separated, they work together in harmony to create a cohesive user experience.
Take Netflix as an example: when you hit play on a video, you’re invoking dozens of microservices that span content delivery, digital rights management, playback telemetry, and more — all operating in a distributed fashion behind the scenes. Each microservice scales independently based on demand and can be updated or recovered in isolation, minimizing downtime and accelerating innovation.
The Distributed Compute Stack: Layers in Focus
To gain a comprehensive understanding of distributed systems, it’s crucial to examine the distributed compute stack — a multi-layered architectural model that underpins the operation of large-scale, modern digital infrastructures. Each layer in this stack plays a specialized role, working in concert to deliver on the core principles of distributed computing: scalability, availability, resilience, and fault tolerance.
At the highest level, the stack begins with application services — the consumer-facing features and functionalities users directly interact with. These are often implemented as microservices that are loosely coupled, independently deployable, and globally distributed. They serve as the orchestrators of user experience, responsible for everything from rendering content to managing personalized recommendations, transactions, or user sessions.
Beneath the application layer lies the service orchestration and communication layer, where technologies like Kubernetes, service meshes (e.g., Istio), and API gateways manage service discovery, routing, load balancing, and network policies. This layer ensures that all services can find and communicate with each other reliably and securely — even across vast, decentralized cloud infrastructures.
Further down the stack, we encounter the data infrastructure layer, which houses databases, message brokers, and caching systems. Distributed data technologies such as Cassandra, Kafka, MongoDB, and Redis live here — each solving a different challenge of data replication, durability, availability, and performance under massive workloads. These systems are engineered to maintain data consistency and throughput, even in the face of node failures or network partitions.
Supporting the data infrastructure is the compute and storage layer, comprised of virtual machines, containers, physical servers, and distributed file systems like HDFS or Amazon S3. This layer handles raw compute power and persistent storage, enabling dynamic resource allocation and high-volume data processing.
At the foundation of the stack lies the network and transport layer, where protocols, software-defined networking (SDN), and cloud interconnects manage global traffic routing, fault-tolerant communication, and latency optimization across regions. It is this invisible layer that allows geographically distributed components to function cohesively and exchange data with minimal delay or disruption.
Understanding this layered architecture is essential not only for systems engineers and architects but for any technologist building cloud-native, scalable platforms. Each layer solves a specific set of distributed challenges, and together, they create the resilient digital backbone that supports everything from real-time messaging to global e-commerce and high-frequency trading.
By exploring the distributed compute stack layer by layer, we uncover the intricate engineering that enables today’s most demanding and sophisticated digital experiences to run smoothly, at scale, and with exceptional reliability.
Layers of the Distributed Compute Stack: From Applications to Infrastructure
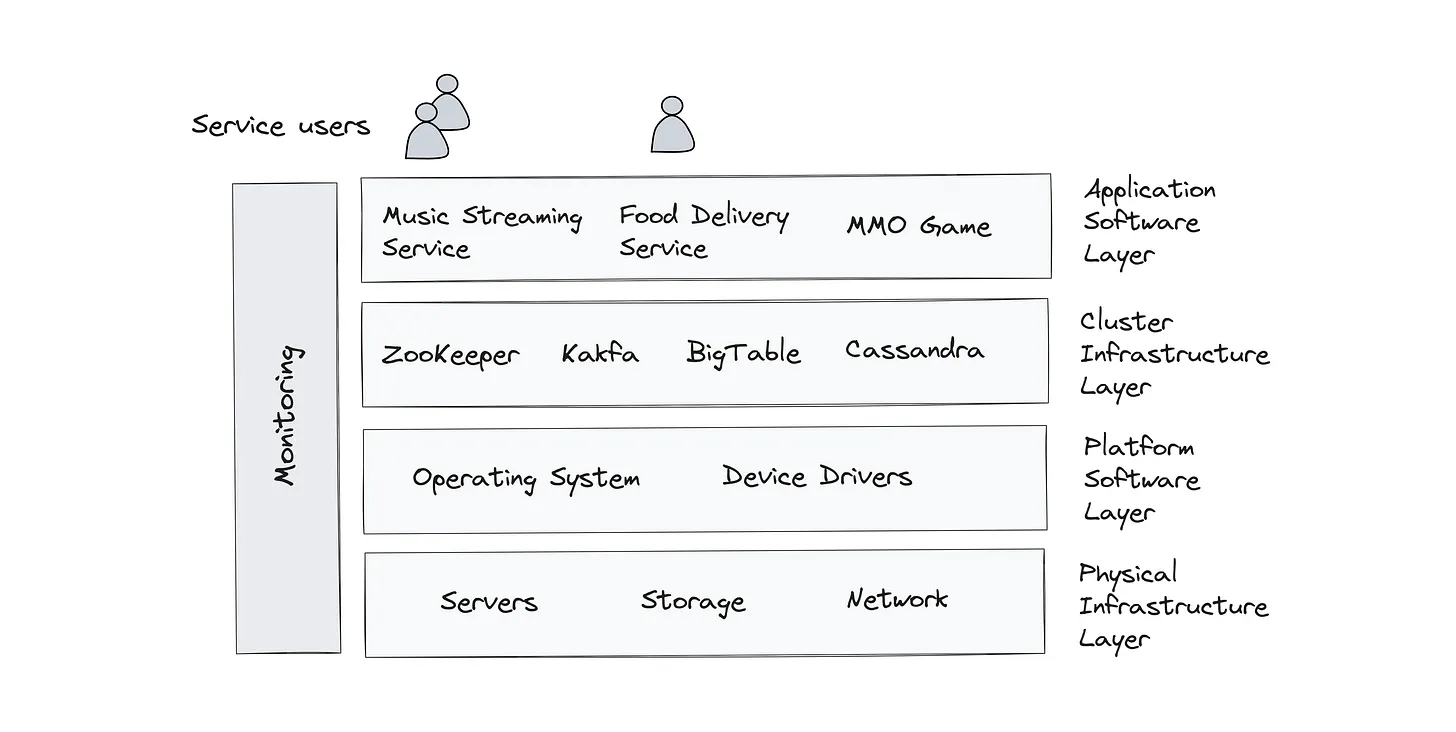
The distributed compute stack is a layered architectural framework that defines how modern digital services are built, operated, and scaled across global infrastructures. From the surface-level applications we interact with every day to the physical infrastructure that powers them, each layer in this stack serves a distinct and essential role.
1. Application Layer — The User Experience
At the top of the stack resides the application software layer, where consumer-facing platforms such as Uber, Spotify, and Netflix deliver intuitive and responsive experiences. These applications rely on numerous microservices orchestrated across distributed environments to provide functionality like user authentication, real-time search, media playback, and personalized recommendations. This is the layer users see and engage with directly, and it depends heavily on the robust layers beneath it to maintain uptime, responsiveness, and reliability.
2. Service Layer — Microservices and Orchestration
Beneath the application layer is the service orchestration layer, which includes tools like Kubernetes, service meshes, and API gateways that manage how services communicate and scale. This layer ensures microservices can discover one another, handle requests gracefully, and maintain secure and load-balanced interactions. It also abstracts deployment complexity, enabling developers to build and ship features rapidly while ensuring platform resilience.
3. Data Infrastructure Layer — Distributed State and Messaging
Next comes the data layer, a critical tier where services like Kafka (event streaming), Redis (caching), Cassandra (NoSQL storage), and MongoDB (document databases) reside. These systems manage massive volumes of stateful data and real-time communication across the application. They’re optimized for fault tolerance, distributed consistency, and replication — ensuring that data is accurate, available, and accessible, even under heavy load or during partial outages.
4. Compute and Storage Layer — Elastic Scalability
Supporting the upper layers is the compute and storage infrastructure, comprising virtual machines, containers, auto-scaling groups, and storage platforms like Amazon S3 and EBS volumes. This layer provides the raw horsepower and disk capacity necessary to process data, serve requests, and store persistent state. It’s built to dynamically scale up or down based on demand, allowing services to grow elastically with user traffic.
5. Network Layer — Global Reach and Redundancy
At the foundation lies the network layer, which manages routing, DNS resolution, peering, load balancing, and content delivery networks (CDNs) across regions and availability zones. This layer is responsible for ensuring packets get where they need to go — quickly, securely, and reliably. It handles the realities of latency, congestion, and failover, often using software-defined networking (SDN) and cloud-native load balancers to ensure global performance.
Understanding these interconnected layers allows us to appreciate how distributed systems operate behind the scenes of the modern internet. Each layer plays a pivotal role in enabling large-scale services to function with resilience and speed — even under extreme demand. This layered approach is foundational to how the digital world scales with confidence and delivers consistently high-quality experiences to users worldwide.
Beneath the Surface: The Cluster Infrastructure Layer
Just beneath the application and service orchestration layers lies a powerful and often underappreciated foundation: the cluster infrastructure layer. This layer is the beating heart of distributed systems, enabling large-scale digital services to store, process, and exchange information reliably across massive global environments.
While users may never directly interact with it, this layer plays a critical role in powering the seamless experiences delivered by applications like Netflix, Uber, and Spotify. It is composed of a suite of specialized distributed systems that manage everything from stateful data to event-driven communication.
Key Components of the Cluster Infrastructure Layer
-
Distributed Databases:
Technologies such as Redis, MongoDB, and Cassandra operate across geographically dispersed clusters to ensure high availability, fault tolerance, and fast access to structured or semi-structured data. These systems are designed to handle large volumes of reads and writes across multiple nodes, ensuring consistency and durability even in the face of node failures or network partitions. -
Message Brokers:
At the core of inter-service communication is Apache Kafka, a distributed event streaming platform that enables decoupled services to publish and subscribe to message topics. Kafka allows real-time data pipelines, asynchronous processing, and audit-friendly logs, making it a cornerstone of modern microservices architectures. -
Distributed Caches:
Tools like Redis and Memcached provide ultra-fast access to frequently requested data by storing it in memory. This reduces the load on primary databases and drastically improves response times for read-heavy services. Caches are especially important for performance-critical features like user session management, personalization, and search autocompletion. -
Distributed File Systems:
These systems, such as HDFS (Hadoop Distributed File System) and Ceph, are optimized for large-scale, fault-tolerant data storage. They break data into blocks, distribute them across multiple nodes, and ensure redundancy for durability. These file systems are essential in data analytics, media streaming, and archival workloads. -
Cluster Coordination Systems:
Components like ZooKeeper and Etcd are the control plane of distributed systems. They manage distributed locks, leader elections, service discovery, and system configuration. These tools ensure consistency and coordination among nodes, particularly during network partitions or rolling upgrades.
Together, these systems form a resilient and scalable infrastructure backbone that underpins the upper layers of modern computing. The cluster infrastructure layer abstracts the complexities of distributed computing, providing developers and platform teams with robust primitives to build high-performance, always-on digital services.
Without this layer, the scalability, responsiveness, and fault-tolerance we’ve come to expect from modern web services would simply not be possible. Understanding its components is essential for architects, engineers, and decision-makers who aim to design systems that are both technically sound and operationally scalable.
Abstracting Complexity for Developers
One of the most powerful advantages of the cluster infrastructure layer is its capacity to abstract the immense complexity inherent in building and managing distributed systems. At scale, the challenges of orchestrating thousands of nodes across global data centers—while maintaining consistency, availability, and resilience—can be staggering. This layer simplifies those challenges and shields application developers from low-level infrastructure concerns.
Consider the tasks handled transparently by this layer:
- Distributed Data Coordination: Whether the system uses strong consistency, eventual consistency, or hybrid models, the infrastructure ensures data is correctly replicated and synchronized across distributed regions.
- Dynamic Cluster Adjustments: As user traffic fluctuates, clusters automatically scale up or down, optimizing resource utilization without developer intervention.
- Low-Level Memory and Storage Operations: Complex optimizations for memory access, disk I/O, and garbage collection are managed under the hood.
- Fault Tolerance and Self-Healing: The system detects failures, reroutes requests, and often recovers automatically without interrupting the end-user experience.
This powerful abstraction frees developers to focus on delivering value at the application level—writing business logic, building user interfaces, and creating new features—without needing to understand or manage the intricate distributed systems powering their code.
At the top of the distributed compute stack lies the application software layer, which contains the familiar consumer-facing services we use daily. From ride-sharing on Uber, to music streaming on Spotify, to video watching on Netflix—these experiences are brought to life through this layer.
Beneath it is the cluster infrastructure layer, housing foundational systems such as:
- Distributed Databases like Redis, MongoDB, and Cassandra
- Message Brokers like Kafka
- Distributed Caches such as Redis
- Distributed File Systems
- Cluster Coordination Systems like ZooKeeper and Etcd
These systems power the core functionality of applications—managing consistency, availability, scalability, and resilience across nodes and regions—without forcing developers to deal directly with these concerns.
The Platform Software Layer: Bridging Infrastructure and Hardware
Beneath the cluster infrastructure layer lies the platform software layer. This tier includes the operating system, device drivers, firmware, and virtualization or container runtime environments. It serves as a critical intermediary between the distributed systems above and the bare-metal hardware below.
This layer ensures compatibility between software and hardware and enables multiple distributed services to run concurrently and efficiently on shared hardware. It handles scheduling, memory management, process isolation, and secure execution, playing a pivotal role in service uptime and reliability.
The Physical Infrastructure Layer: Where Software Meets Silicon
At the base of the compute stack is the physical infrastructure layer—the tangible backbone of all computation. This includes:
- Compute Nodes: Physical servers housed in data centers, executing workloads.
- Storage Media: Hard disk drives, NVMe SSDs, and other persistent storage devices.
- RAM: Volatile memory supporting real-time processing and caching.
- Data Center Networking: High-throughput switches and routers linking all components together.
This layer is optimized for performance, reliability, and efficiency at hyperscale. Data centers span continents and are engineered to support thousands of racks, each with its own thermal, power, and redundancy controls.
Observability: The Vertical Layer Spanning the Stack
Overlaying every layer of the stack is a critical meta-layer: observability.
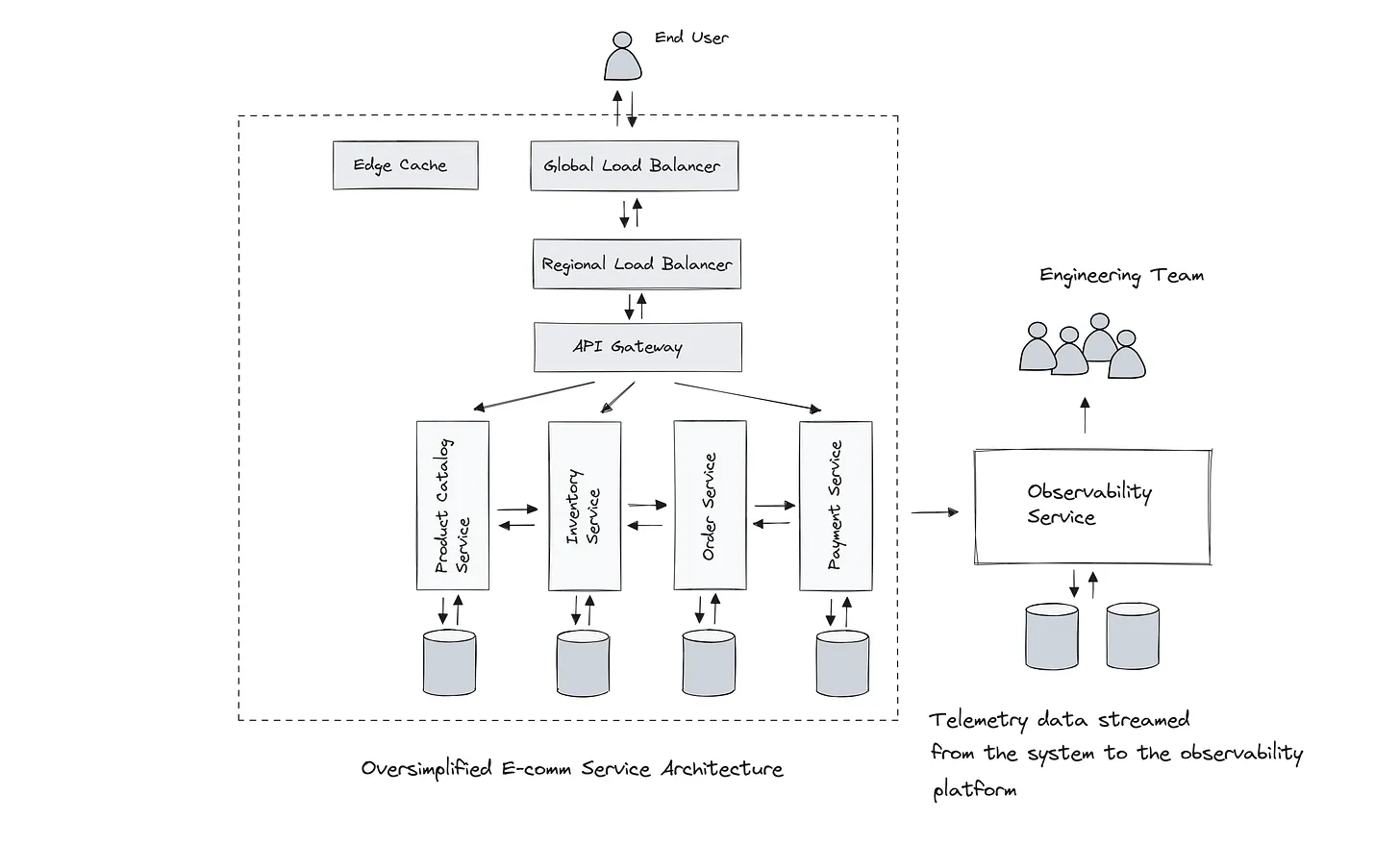
Observability enables organizations to monitor, measure, and troubleshoot every layer in real time. It captures:
- Uptime and Availability Metrics
- Latency and Throughput Trends
- Resource Utilization
- Error and Failure Rates
Observability tools—like Prometheus, Grafana, OpenTelemetry, and custom dashboards—are essential for maintaining SLAs and providing insights during outages or anomalies.
Through this layered architecture—from user-facing applications to metal servers and across observability tooling—the modern compute stack offers a blueprint for building reliable, scalable, and performant digital services in a globally distributed world.
Systems programming
Now that we have an idea of the difference between a distributed web service (running at the top of the compute stack) and a distributed system that runs across nodes in a cluster, interacting with the hardware. Let’s step into the realm of systems programming.
Systems programming primarily entails writing performant software that directly interacts with the hardware and makes the most of the underlying resources.
When we run this software on multiple nodes in a cluster, the system becomes distributed in nature, entailing the application of multiple concepts.
Distributed systems fundamentals
The nodes of our distributed system communicate over the network and the system should address the complexities of network communication, concurrency, data consistency and fault tolerance.
This requires knowledge of networking protocols such as TCP/IP, HTTP, serialization mechanisms and message-passing techniques like gRPC, REST, etc.
To keep the data consistent between the nodes, including keeping the nodes in sync, we need to understand consensus algorithms like Raft and Paxos, as well as the CAP theorem and distributed transactions.
To manage distributed transactions in a scalable and resilient way, distributed services leverage techniques such as distributed logging, event sourcing, state machines, distributed cluster caching, and such.
To implement high availability, we need to be aware of concepts like redundancy, replication, retries, and failover. For scalability, several load-balancing strategies are leveraged, such as sharding, partitioning, caching, implementing dedicated load balancers, and so on.
These are foundational distributed systems concepts that are applicable when implementing a scalable, available, reliable, and resilient system.
System Design, Architecture, and the Role of Programming Languages in Distributed Systems
As we ascend the layers of the distributed compute stack, we eventually reach the point where theoretical underpinnings meet practical implementation—this is the domain of system design and architecture. These are not just buzzwords; they represent the essential engineering mindset needed to build scalable, reliable, and high-performance web applications. If distributed systems form the nervous system of the digital world, then system design is the brain that orchestrates how each component communica…
System design is where we begin applying the principles of distributed computing to real-world services—everything from designing APIs to balancing loads across servers, managing data consistency across nodes, and gracefully handling outages. It’s here we consider whether a service should be implemented as a monolith or decomposed into microservices; whether to use message queues for asynchronous processing; and how to design around constraints like latency, throughput, and data consistency.
This space is also where we explore architectural patterns and design tradeoffs. From event sourcing to publish-subscribe messaging, from circuit breaker patterns that prevent cascading failures to CQRS (Command Query Responsibility Segregation) for read/write optimization—these are the tools that allow engineers to move from theory to scalable reality.
In practice, you might be building a service like Uber that needs to balance ride-matching in real time, or a video platform like Netflix where content delivery must remain seamless under peak loads. These aren’t trivial challenges—they require deep architectural thinking backed by the fundamentals of system design.
Choosing the Right Language for Distributed Systems
Of course, designing a system on paper is only the first step. The actual implementation requires choosing the right programming language—one that can meet the demands of a distributed environment.
Distributed systems aren’t your average applications. They need to perform under stress, operate reliably under partial failure, and be efficient with hardware resources. That’s why they are often built using systems programming languages—languages that offer low-level control over memory, CPU, I/O, and concurrency.
Languages like C and C++ have long been trusted for building performance-critical components like in-memory databases, file systems, or operating system modules. Rust is a modern alternative that brings safety without compromising speed, offering a powerful toolset for writing ultra-low-latency services.
Then there’s Go, purpose-built for building distributed systems. Its concurrency model, powered by goroutines and channels, makes it a favorite for cloud-native infrastructure. Many foundational systems, like Kubernetes, Docker, and CockroachDB, are written in Go because of its balance between performance and ease of development.
Java, while not always categorized strictly as a systems language, offers mature tooling, portability via the JVM, and robust concurrency features. It powers distributed data systems like Apache Hadoop, Apache Kafka, Cassandra, and Elasticsearch. Scala, a JVM language used to build Kafka, bridges functional and object-oriented paradigms while leveraging Java’s ecosystem.
Languages like Elixir and Erlang, though niche, shine in domains where high concurrency and fault tolerance are essential—ideal for messaging systems and telecom infrastructure.
That said, language choice is ultimately about fit. If you’re exploring system design from a learning perspective, your priority should be mastering the concepts. You can build prototypes in Python, JavaScript, or any other language you’re comfortable with.
Personally, I’ve implemented TCP/IP servers in Java and am currently building a message broker in Go to take advantage of its concurrency support. What matters most is understanding how distributed components interact, how to handle failure, and how to reason about consistency and scalability—not the language itself.
In production systems, the stakes are higher—ultra-low latency or deterministic memory use might require Rust or C++. But even then, the decision isn’t absolute. Modern systems are polyglot. A distributed database backend may be written in Rust, but its management API could be served via a Go-based microservice.
Distributed systems and system architecture aren’t isolated domains—they are part of a continuum. From hardware to cloud APIs, from protocol design to application UX, everything is interconnected. Choosing the right language, designing the right architecture, and applying the right patterns is what enables us to build resilient systems that scale to millions.
Whether you’re aiming to design the next Netflix or just preparing for system design interviews, your journey should begin with a deep understanding of these principles. Concepts like consistency models, fault tolerance, latency trade-offs, and service orchestration form the toolkit of every systems thinker—and the best part? Once you’ve mastered them, you can build anything.
Data Structures and Algorithms
In addition to mastering distributed systems, it’s equally important to understand the fundamentals of data structures, networking, and operating systems.
As emphasized earlier, you don’t need to master everything up front—just learn what’s required as you progress. The topics listed here serve as a helpful reference.
Data structures and algorithms (DSA) are foundational to building performant and scalable systems. When handling systems that serve millions of users concurrently, the ability to process data and requests efficiently becomes paramount—and that’s where DSA comes in.
For instance:
- B-trees and hash tables are essential for designing storage engines and building efficient indexing mechanisms in databases.
- Merkle trees play a critical role in enabling data integrity verification and synchronization across distributed systems.
- Bloom filters are leveraged in systems like distributed caches and databases to support fast membership checks while minimizing memory usage.
- Distributed consensus algorithms (like Paxos and Raft) ensure consistency and coordination across multiple nodes in a distributed setup.
- Consistent hashing helps distribute data evenly and enables smooth scalability without major data reshuffling.
- Dynamic routing algorithms, including weighted and adaptive strategies, are applied in load balancers and distributed proxies to optimize request handling and resource utilization.
These examples underscore how DSA knowledge directly impacts your ability to build fast, reliable, and efficient distributed systems. While you can build prototypes in any language of your choice, understanding the underlying logic and principles is what enables meaningful innovation at scale.
Networking
A strong grasp of networking fundamentals is essential when working with distributed systems. This includes low-level topics like socket programming, TCP/IP, UDP, and HTTP protocols. Understanding how data is transmitted across machines, how connections are established, and how packets are routed is foundational for designing systems that are robust and performant at scale.
Distributed systems rely heavily on reliable communication protocols. TCP/IP, for instance, is the backbone protocol suite used to transmit data accurately and reliably between nodes across a network. HTTP, meanwhile, is ubiquitous in client-server communication on the web and underpins nearly all modern web-based distributed services.
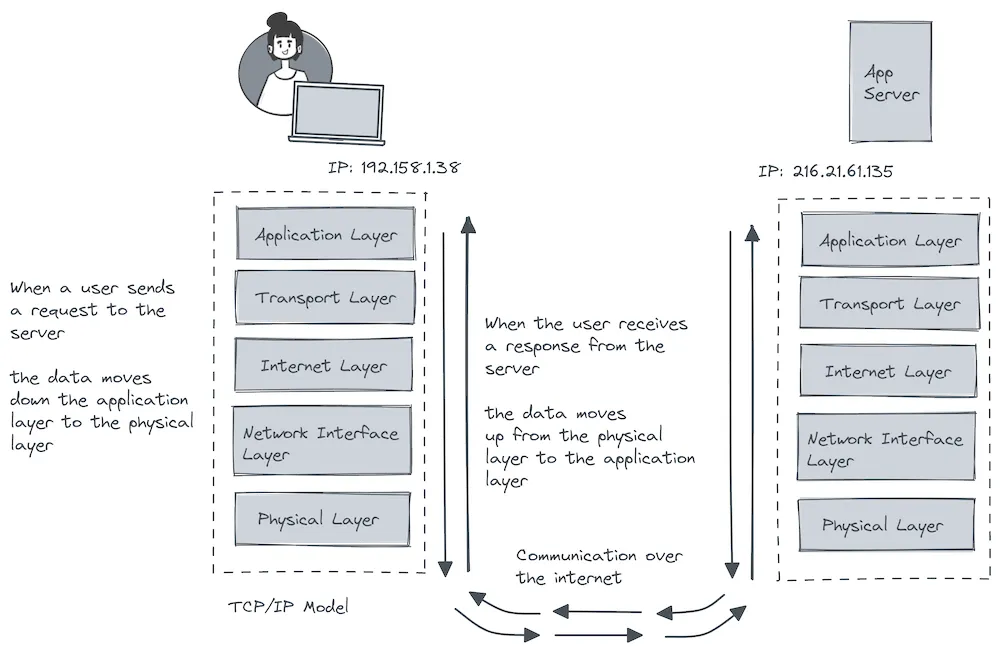
Beyond protocols, an understanding of network topologies is also crucial. Proper topology design can reduce communication overhead, optimize latency, and ensure better fault tolerance and scalability when deploying services across cloud regions and availability zones globally.
Operating Systems
Equally important is a deep understanding of operating system concepts. Memory management—encompassing virtual memory, paging, allocation strategies, and more—plays a key role in the efficient execution of distributed applications.
Resource management, inter-process communication (IPC), and scheduling algorithms directly influence how tasks are distributed and executed across processes and threads. Concepts such as locks, semaphores, and monitors ensure synchronization, prevent race conditions, and maintain consistency in concurrent operations.
The distinction between user space and kernel space also becomes vital when building systems that require close-to-the-metal performance optimization. A good example is Apache Kafka, which implements zero-copy optimization—bypassing file system caches and directly accessing disk—to achieve ultra-low latency and high throughput.
These system-level optimizations are not just academic; they are foundational in real-world applications like Kafka, Hadoop, and Google BigTable. These systems are built with an intimate understanding of OS internals and file system architectures to manage massive-scale data storage and retrieval efficiently.
Deployment and Cloud: Bringing Distributed Systems to Life
Designing and building a distributed system is only part of the journey. To truly validate its behavior, resilience, and performance, the system must be deployed in a real-world distributed environment. This is where deployment strategies and cloud infrastructure fundamentals come into play.
Modern deployment is rarely done manually or on bare-metal servers. Instead, containerization technologies like Docker allow developers to package software along with its dependencies into portable units. These containers ensure consistent behavior across development, testing, and production environments.
To manage, scale, and orchestrate these containers in distributed environments, Kubernetes has become the de facto standard. It enables automated deployment, scaling, and management of containerized applications across clusters of machines. Kubernetes handles failover, service discovery, load balancing, rolling updates, and even self-healing through auto-restarts or rescheduling of failed containers.
However, container orchestration is only one part of the equation. Distributed systems often span across cloud platforms such as AWS (Amazon Web Services), Google Cloud Platform (GCP), or Microsoft Azure. These platforms provide the underlying compute, storage, networking, and security infrastructure required to host and scale distributed services globally.
Understanding how to leverage these cloud services—including virtual machines, managed Kubernetes clusters, serverless offerings, load balancers, message queues, and monitoring tools—is crucial. In addition, concepts such as multi-region deployment, availability zones, vendor lock-in, cloud-native infrastructure, and deployment workflows are essential for building fault-tolerant and globally available systems.
Final Thoughts: Building Blocks for Modern Distributed Systems
Distributed systems form the foundation of today’s most resilient, scalable, and high-performance digital platforms. From global messaging services to real-time analytics, the principles covered—from consistency models and infrastructure layers to deployment strategies and cloud integration—are not just academic; they are the practical realities shaping how modern software is built and operated.
Understanding these foundational concepts is not a luxury but a necessity for anyone looking to architect or contribute meaningfully to distributed environments. Whether you’re optimizing a global microservices architecture, implementing a high-throughput messaging broker, or simply preparing for system design interviews, the knowledge you’ve acquired across these sections empowers you to approach distributed challenges with clarity and confidence.
As systems continue to scale across geographies and grow in complexity, it is this deep, layered understanding that separates a good engineer from a great one. Keep learning, keep building, and remember: distributed systems aren’t just about infrastructure—they’re about delivering experiences that are seamless, reliable, and built to last.


