Unlocking Performance and Intelligence: Semantic Caching for Next-Generation LLM Applications
As organizations increasingly deploy Large Language Models (LLMs) in real-world applications, they encounter growing challenges related to latency, scalability, and compute cost. Semantic caching emerges as a transformative solution—one that goes beyond conventional caching by understanding the meaning and intent behind user queries.
Rather than treating each query as a string of characters, semantic caching leverages vector embeddings and semantic similarity to intelligently identify and reuse responses to conceptually similar queries. This approach dramatically enhances both the efficiency and intelligence of LLM-powered applications by reducing redundant computations and enabling near-instantaneous responses to repeated or similar inputs.
Unlike traditional caching mechanisms that rely on exact keyword or token matches, semantic caching stores and retrieves results based on contextual meaning, enabling smarter, faster, and more adaptive experiences for users. It’s especially critical in Generative AI environments where inference costs are high and responsiveness is key.
Whether powering customer-facing chatbots, knowledge assistants, or enterprise search interfaces, semantic caching delivers the dual benefits of cost savings and enhanced user satisfaction, making it a foundational building block for modern LLM architectures.
Understanding Semantic Caching: Context-Aware Intelligence for High-Performance LLM Systems
In the era of intelligent applications, where user interactions must be fast, relevant, and efficient, semantic caching emerges as a game-changing strategy. Unlike traditional caching mechanisms that depend on exact string matches, semantic caching interprets and stores the meaning and context of user queries. This allows systems to retrieve information based on intent, not just text—resulting in faster and more relevant responses, particularly in Large Language Model (LLM)-powered applications.
By leveraging vector embeddings and semantic similarity scoring, semantic caching empowers systems to identify when two queries—despite being worded differently—seek the same information. This enables previously computed answers to be reused intelligently, bypassing the computational overhead of generating a new response each time.
A Librarian That Understands You
Imagine a librarian who doesn’t just know where books are shelved but understands why you’re asking a question. This librarian considers your reading history, your learning goals, and even your mood. Instead of mechanically retrieving a book by title, they hand you the one that best matches your intent. That’s how semantic caching works—intelligently matching meaning to accelerate delivery and enhance experience.
Why This Matters
Semantic caching enhances:
- Response Speed: By serving cached responses to semantically similar queries.
- Relevance: By prioritizing contextual meaning over keyword matches.
- Cost Efficiency: By reducing redundant calls to compute-heavy LLMs.
- Scalability: By improving response throughput in high-traffic systems.
As demand grows for scalable, intelligent interfaces—whether in customer service, enterprise knowledge retrieval, or digital assistants—semantic caching becomes a cornerstone of next-gen system design.
Semantic Caching vs. Traditional Caching: A Leap from Speed to Intelligence
In the world of high-performance applications, caching has always been a fundamental technique for improving response times and reducing backend strain. Traditional caching, such as key-value stores, operates on a simple premise: if a specific query or request has been made before, serve the same precomputed response. This model works well for static or frequently repeated data but falls short in more dynamic, intelligent systems—especially those powered by Large Language Models (LLMs) or semantic search engines.
This is where semantic caching introduces a revolutionary leap forward. Rather than storing data based on exact match keys or URLs, semantic caching interprets the underlying meaning and intent of a user’s query. It leverages AI-driven vector embeddings to represent both incoming queries and stored data semantically. This allows the system to recognize conceptual similarity—even if the wording changes—and deliver relevant, high-quality responses without needing to re-run expensive computations.
For example, a traditional cache would treat “What are the health benefits of turmeric?” and “How does turmeric help the body?” as two unrelated questions. In contrast, semantic caching understands that both queries aim to retrieve the same general knowledge and can serve a single, intelligent response to both—dramatically improving performance while preserving accuracy.
Key Differences at a Glance
| Feature | Traditional Caching | Semantic Caching |
|---|---|---|
| Matching Logic | Exact match (string, URL, ID) | Semantic similarity (meaning-based) |
| Data Awareness | Context-agnostic | Context-aware, meaning-driven |
| Use Case Suitability | Static content, repeated identical queries | Dynamic queries, LLMs, search, NLP applications |
| Response Flexibility | Rigid (no match = no hit) | Adaptive (matches intent across phrasing variations) |
| Cost Efficiency | Limited to high-hit identical requests | Broad efficiency via intelligent reuse of semantically similar data |
The Strategic Advantage
Semantic caching doesn’t just make apps faster—it makes them smarter. It shifts caching from a blunt instrument to a precision tool that understands user goals, making it especially valuable in AI-enhanced workflows. By reducing redundant LLM calls, offloading expensive compute tasks, and surfacing high-quality answers faster, semantic caching plays a vital role in scaling GenAI and search systems efficiently.
Key components of semantic caching systems
- Embedding model – Semantic caching systems use embeddings. These are vector representations of data that help assess the similarity between different queries and stored responses.
- Vector database – This component stores the embeddings in a structured way. It facilitates fast retrieval based on semantic similarity instead of using exact matches.
- Cache – The central storage for cached data, where responses and their semantic meaning are stored for future use and fast retrieval.
- Vector search – A key process in semantic caching, this step involves evaluating the similarity between incoming queries and existing data in the cache to decide the best response– fast.
These components boost app performance with faster, more context-aware responses. The integration of these elements into LLMs transforms how models interact with large datasets, making semantic caching an important part of modern AI systems.
Accelerating LLM-Powered Applications: The Performance Edge of Semantic Caching
As organizations integrate Large Language Models (LLMs) into real-time applications—from intelligent chatbots to complex analytics—performance and responsiveness become mission-critical. These applications must deliver fast, accurate, and context-aware responses under demanding workloads. This is where semantic caching proves indispensable.
Unlike traditional approaches that cache results only when exact matches occur, semantic caching introduces a layer of intelligent retrieval, where context and meaning guide the reuse of previously generated outputs. By recognizing semantically similar queries and reusing relevant answers, semantic caching dramatically reduces compute cycles, lowers latency, and boosts scalability across LLM architectures.
Real-World Impact: From Theory to Results
Consider an enterprise chatbot powered by a generative model. When users ask common questions like “How do I file an IRS Form 990?” or “Instructions for tax-exempt organizations,” a system without semantic caching must reprocess the request in full—wasting valuable resources. However, with semantic caching in place, the system can identify the similarity between these queries and reuse a previous response, reducing latency by up to 15X. This is demonstrated in this open-source chatbot stack, which retrieves answers from internal document repositories.
This performance leap doesn’t just save time—it ensures a smoother user experience and reduces operational costs.
Broader Applications
Semantic caching is particularly effective in:
- Customer Support Bots: Providing fast and consistent answers to FAQs and dynamic queries.
- Legal and Compliance Research: Rapidly surfacing previous legal interpretations or document summaries.
- Healthcare Informatics: Answering diagnostic or pharmaceutical inquiries based on a growing corpus of data.
- Scientific Research Tools: Enabling quick retrieval of semantically related experimental results or publications.
By aligning data retrieval with user intent, semantic caching ensures not only speed—but also precision and relevance. It transforms LLM-powered applications from merely reactive tools into proactive, intelligent systems.
As semantic caching becomes a standard architectural pattern for GenAI systems, it’s clear that making apps faster is no longer just a backend concern—it’s a strategic advantage for the entire user experience.
Seamless Integration: How Semantic Caching Works with LLMs
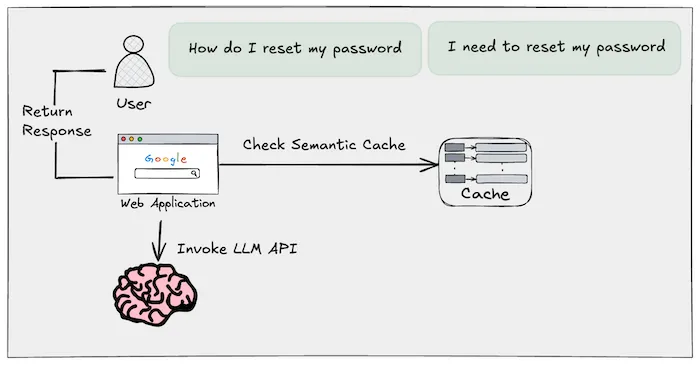
In modern LLM-powered applications, vector search is the engine that powers semantic caching. Rather than relying on traditional keyword lookups, vector search enables systems to retrieve content based on semantic similarity—the closeness in meaning between a user’s query and previously cached responses.
When a query is received, it’s first transformed into a vector using an embedding model. This vector captures the essence—the intent and context—of the query. The system then compares this vector against a database of previously stored vectors (cached responses), identifying entries with high semantic overlap. If a match is found, the response is served directly from cache, bypassing the need to invoke the LLM again.
This intelligent reuse not only accelerates response times but also significantly reduces inference costs and boosts system scalability. Tools like Redis Vector Search are purpose-built to perform these high-speed, high-accuracy comparisons, making them ideal for GenAI architectures that demand both performance and relevance.
Enhancing Performance and Efficiency: Practical Use Cases of Semantic Caching
Semantic caching isn’t just a technical enhancement—it’s a strategic accelerator for AI-powered applications. By intelligently reusing semantically similar responses, it dramatically reduces the computational overhead of repeated queries, lowers latency, and enables real-time responsiveness. Below are key use cases that showcase the transformative impact of semantic caching across diverse industries:
Automated Customer Support
In high-volume customer service environments, speed and consistency are critical. Semantic caching allows AI-driven support systems to rapidly identify and serve answers to frequently asked questions, even when phrased differently by different users. Instead of rerunning an LLM query for each request, cached responses—matched by meaning—can be served instantly.
- Impact: Reduces response time, improves customer satisfaction, and lowers LLM compute costs.
- Example: “How do I reset my password?” and “I can’t log in—what do I do?” return the same semantically cached answer, streamlining support.
Real-Time Language Translation
In translation platforms and multilingual interfaces, semantic caching allows common phrases and sentence structures to be reused rather than retranslated. By caching translations semantically, systems can quickly serve previously translated content without sacrificing accuracy.
- Impact: Speeds up translation, reduces redundancy, and enhances consistency across similar requests.
- Example: In a global e-commerce app, recurring product descriptions or shipping notices are retrieved instantly via semantic cache.
Content Recommendation Systems
Recommendation engines rely heavily on matching user intent to relevant content. Semantic caching enables these systems to recognize and serve results aligned with previously processed queries, ensuring recommendations are not only fast but deeply relevant.
- Impact: Improves user engagement, reduces processing time, and supports personalization at scale.
- Example: A streaming service recommends similar shows based on past searches like “dystopian sci-fi” or “futuristic thrillers,” which are semantically linked through cached intent.
As these use cases show, semantic caching isn’t just a backend optimization—it’s a core enabler of real-time, intelligent digital experiences. Whether it’s enhancing responsiveness, improving relevance, or reducing infrastructure load, semantic caching offers a measurable competitive advantage in today’s GenAI applications.
Ushering in a New Era of Intelligent Applications
We are entering a transformative era where semantic caching is no longer optional—it’s essential. As the backbone of next-generation AI applications, semantic caching redefines how data is stored, accessed, and leveraged in real time. It marks a fundamental shift from raw compute-driven inference to intent-aware, performance-optimized intelligence.
By interpreting and caching the meaning behind queries, semantic caching drastically reduces redundant processing, accelerates response times, and elevates the accuracy of outputs. This isn’t just about speed—it’s about delivering contextually relevant, high-confidence answers in milliseconds. In a world where user expectations hinge on instant insights and seamless interactions, semantic caching becomes the force multiplier that turns good apps into great ones.
Looking ahead, its importance will only grow. As enterprise LLM workloads become more complex, and real-time interaction becomes the norm, caching strategies must evolve beyond keywords and static rules. Generative AI applications are evolving, with deeper chains of reasoning, multi-turn dialogue, and increasingly large context windows—all of which stretch traditional infrastructure. Meanwhile, the rising cost of inference with premium models makes efficiency a strategic imperative.
Semantic caching stands at the intersection of these challenges and opportunities. It empowers organizations to scale GenAI capabilities without scaling cost. It delivers both performance and precision. And most importantly, it prepares your AI infrastructure for what’s next.
The future of responsive, intelligent, and cost-efficient AI applications starts with smarter caching. Semantic caching is the unlock.