
Understanding the Fundamentals of Database Consistency
As we scale our systems to operate across regions and availability zones, we inevitably face trade-offs that are at the heart of distributed system design. These trade-offs are most famously captured by the CAP Theorem, which states that a distributed system can only guarantee two of the following three at a given time: Consistency, Availability, and Partition Tolerance. More specifically, in the face of a network partition, a system must choose between remaining available or maintaining consistency.
The conversation doesn’t end there. The PACELC Theorem, an extension of CAP, introduces a more nuanced view: if a partition occurs, you must choose between Availability and Consistency (PAC), but else, even when the system is functioning normally, you still have to choose between Latency and Consistency (ELC). This subtle yet powerful distinction highlights that trade-offs around consistency are not just edge-case considerations but core design decisions in all distributed systems.
What is Database Consistency?
At its core, consistency in databases means that every read receives the most recent write—or an error. In distributed databases, this gets more complex. Multiple nodes in different locations might hold copies of the same data, and ensuring they remain in sync becomes a non-trivial task.
Different systems handle consistency in different ways, and these are commonly referred to as consistency models or levels of consistency. The choice of consistency level directly impacts the system’s behavior, developer experience, user expectations, and overall performance.
Real-World Context: Messaging Services like Discord
To better understand how consistency plays out in the real world, consider a messaging platform like Discord. Imagine a user sends a message to a channel. The sender expects the message to appear immediately. At the same time, all recipients across the world should also see it with minimal delay. However, ensuring that every user sees the message at exactly the same time—especially across geographically distributed data centers—is incredibly hard.
This is where eventual consistency often comes into play. Discord might choose to show the sender their message immediately (via local write acknowledgment) and propagate the message to other users shortly after. While it might only take milliseconds, it’s still not strictly consistent from a database theory perspective. Yet, for most users, the experience feels seamless.
Exploring Database Consistency Levels
When designing or working with distributed databases, consistency becomes one of the most critical yet nuanced considerations. As distributed systems scale across multiple nodes, regions, and availability zones, ensuring that data remains coherent and up-to-date for all users becomes increasingly complex.
At the core of this challenge lie different consistency levels, which define how and when the system guarantees the visibility of data changes to its clients. These levels offer a spectrum of trade-offs between performance, latency, availability, and user experience.
The Two Pillars: Strong and Eventual Consistency
Most distributed databases support at least two foundational consistency models:
-
Strong Consistency:
Strong consistency ensures that every read reflects the most recent write for a given piece of data. Once a write operation is acknowledged, any subsequent read will return that updated value, regardless of the node handling the request.
This model is ideal for scenarios where correctness and data integrity are paramount, such as financial transactions, inventory management, or systems of record.
However, the trade-off is increased latency and potentially reduced availability during network partitions, as nodes must coordinate to ensure consistency before responding. -
Eventual Consistency:
Eventual consistency guarantees that, given enough time and the absence of new updates, all replicas of a piece of data will converge to the same value.
This model allows for much higher availability and lower latency, as reads and writes do not need to coordinate across all nodes in real-time.
It is commonly used in systems like messaging platforms, social media feeds, and content delivery networks, where slight delays in consistency are acceptable to provide a seamless user experience.
Beyond the Basics: Tunable and Intermediate Consistency Models
Between strong and eventual consistency lies a rich spectrum of tunable and specialized consistency levels, often provided by modern distributed databases like Cassandra, Cosmos DB, or DynamoDB. These models enable more granular control over data consistency based on specific use cases:
-
Causal Consistency:
Preserves the cause-effect relationship between operations. If operation A causes operation B, then any user who sees B is guaranteed to have also seen A. This model is especially useful in collaborative applications where action ordering is important. -
Read-Your-Writes Consistency:
Guarantees that once a client has written data, any subsequent read by the same client will reflect that write. This model is critical in user-centric applications like profile updates or dashboards, where users expect immediate feedback on their changes. -
Monotonic Read Consistency:
Ensures that if a user has seen a particular value for a piece of data, they will not later see an older value. This avoids “time-travel” reads and is useful for ensuring progress in user sessions or paginated data views. -
Monotonic Write Consistency:
Guarantees that write operations from a single user are applied in the order they were issued. This model helps preserve data integrity when users perform sequential updates. -
Session Consistency:
Offers a combination of guarantees (often read-your-writes and monotonic reads) within the context of a user session. It provides a balance between usability and performance, making it ideal for applications with interactive user interfaces.
Strong Consistency: Ensuring a Single Source of Truth
Strong consistency is a foundational property in distributed systems that ensures all users—regardless of their geographic location, cloud region, or the specific server node they connect to—observe the same state of data at any given moment in time. In other words, once a write is acknowledged, every subsequent read across the entire distributed system must reflect that change. This means there’s a global single version of truth, and no user sees stale or out-of-sync data.
This level of consistency is critical in mission-critical applications where data accuracy and temporal alignment are non-negotiable. Typical use cases include:
- Financial systems: where order execution, account balances, and settlements must be reliably reflected everywhere immediately.
- Online booking systems: where ticket availability or room reservations must not be double-booked.
- Healthcare applications: where patient records and medication data must be up-to-date and synchronized across hospitals and devices.
- Collaborative platforms: where users editing or viewing shared documents must see the same version.
Strong Consistency in a Real-World Messaging Platform
Let’s consider a global messaging application, such as a chat service similar to Slack or Discord. Imagine users from New York, London, and Singapore all participating in the same channel. If one user edits or deletes a message, strong consistency ensures that all users see this edit or deletion reflected immediately—regardless of their location or which data center they’re connected to.
Without strong consistency, the situation becomes problematic:
- A user in Singapore might still see the original unedited message.
- Meanwhile, a user in New York sees the updated one.
- This discrepancy can lead to miscommunication, fragmented conversations, or even loss of trust in the platform.
To maintain a seamless, synchronized experience, strong consistency guarantees that all users receive the same version of the message state, no matter where they are. This eliminates confusion and ensures that everyone is operating on the same information.
How Strong Consistency Is Achieved
Achieving strong consistency in a globally distributed system is technically demanding and comes with its own trade-offs. Here’s how it’s typically implemented:
-
Synchronous Replication Across Nodes:
A write (e.g., an edit or deletion of a message) is only acknowledged once the update has been replicated and confirmed by all participating nodes across cloud regions. Until that happens, the change is not visible to any user. -
Quorum-Based Write and Read Protocols:
Systems like Apache Cassandra or Amazon DynamoDB can be configured to use quorum reads and writes—ensuring that a majority of nodes must agree on a read or write before proceeding. This helps enforce consistency. -
Global Transaction Managers or Consensus Algorithms:
Advanced distributed databases use consensus protocols such as Paxos or Raft to coordinate write operations across geographically distributed clusters. These protocols ensure that conflicting updates are avoided and that all nodes agree on a single consistent view of data. -
Write Funneling Through a Central Region:
To reduce complexity, some architectures restrict writes to a specific region (or a few select regions), funneling all update operations through those areas. While this can improve consistency, it may also introduce latency and single points of failure.
The Trade-Offs: Consistency vs. Latency and Availability
Ensuring strong consistency means sacrificing ultra-low latency and, at times, availability—as outlined in the CAP theorem and further refined by the PACELC theorem.
For example:
- In the case of a message edit, users will only see the update after it has propagated across all regions, introducing a noticeable delay.
- If a region is temporarily unavailable or network partitions occur, the system might have to block reads or writes entirely to preserve consistency, affecting uptime.
- Concurrent writes to the same entity (e.g., two users editing a message at once) introduce additional complexity, requiring conflict resolution or write serialization, often by prioritizing a primary write region.
Thus, while strong consistency guarantees correctness and alignment across users, it must be balanced against real-time responsiveness and global availability.
When to Use Strong Consistency
Strong consistency should be chosen when correctness is paramount and eventual convergence is not acceptable—particularly when:
- The data influences financial or legal decisions.
- Real-time collaboration depends on synchronized state.
- Conflicting data could result in business or user harm.
Although more demanding in terms of infrastructure and latency, strong consistency plays a crucial role in upholding user trust, data integrity, and system reliability in distributed applications. It is a commitment to precision—even when the trade-offs are complex—ensuring a coherent and predictable user experience across the globe.
Eventual Consistency: Favoring Availability and Partition Tolerance
Eventual consistency is a consistency model used in distributed systems to prioritize availability and partition tolerance over immediate consistency. It guarantees that, in the absence of new updates, all replicas in a distributed system will eventually converge to the same value. This model relaxes the requirement that all users see the most recent update instantly, which enables greater performance, scalability, and fault tolerance—especially across geographically distributed systems.
Eventual Consistency in a Global Messaging Platform
Let’s revisit the example of a messaging platform similar to Discord. When a user edits a message in an eventually consistent system, the update is applied immediately to the local region’s database node. Users in the same cloud region (e.g., North America) will see the edited message instantly. However, users in other regions (e.g., Europe or Asia-Pacific) may still see the previous, unedited version of the message until the change is asynchronously replicated to their local nodes.
This creates a temporary state where different users see different versions of the same data—a phenomenon known as data staleness. Over time (typically within milliseconds to seconds), the replication completes, and all nodes reflect the updated message, achieving consistency eventually.
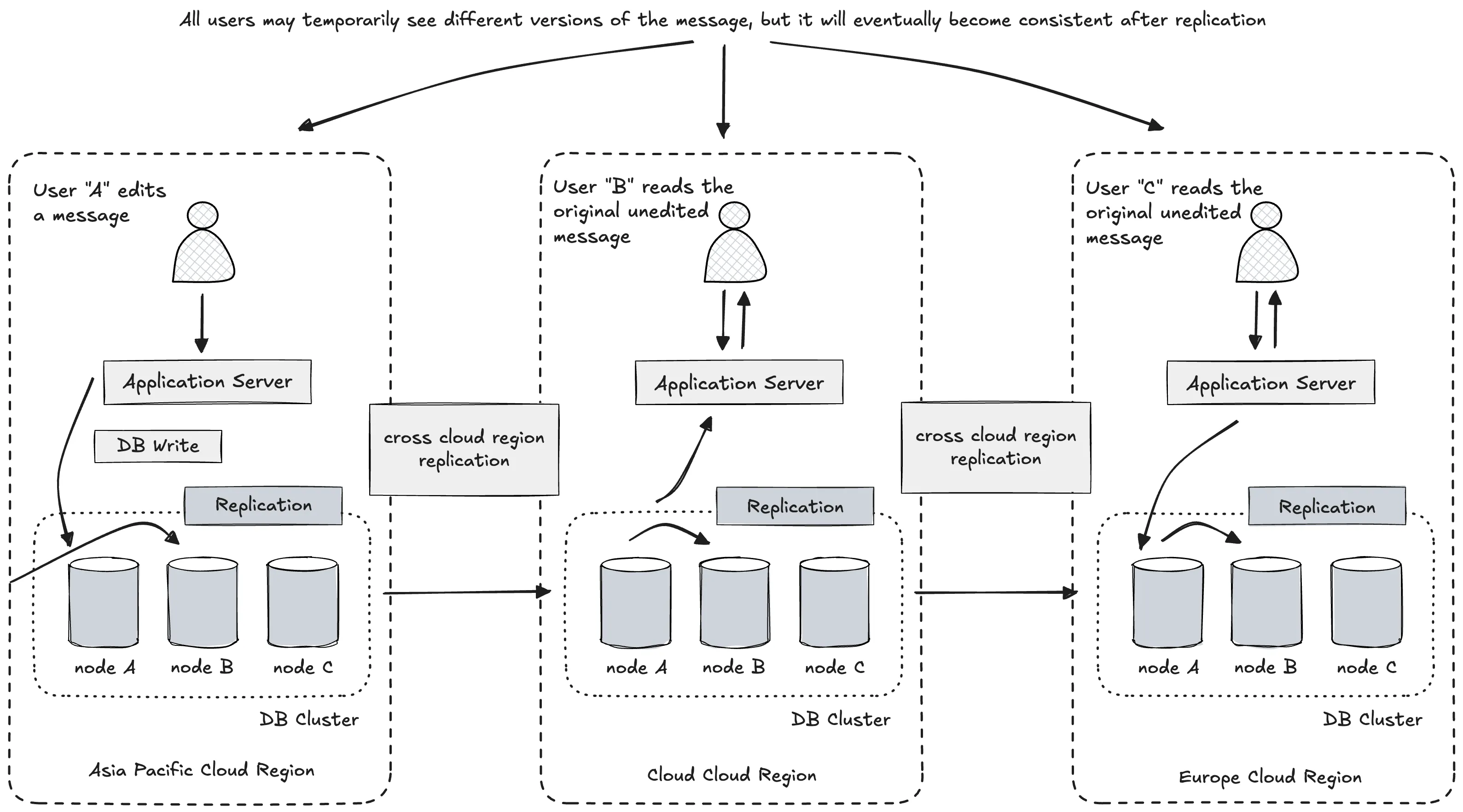
In this model:
- No locks are imposed on database reads or writes.
- Writes are processed locally and propagated asynchronously.
- The system favors low latency and high availability, especially during network partitions.
Trade-Offs of Eventual Consistency
The primary trade-off in eventual consistency is user experience vs. system resilience:
| Benefit | Implication |
|---|---|
| High Availability | Users can read and write data even during network partitions or regional outages. |
| Low Latency | Local writes and reads are extremely fast because they don’t require coordination with global nodes. |
| Scalability | Systems can horizontally scale across regions and data centers without centralized bottlenecks. |
However, the downsides must also be carefully considered:
- Inconsistency Windows: Users may briefly encounter stale or conflicting data.
- Complex Conflict Resolution: When multiple users update the same data concurrently in different regions, resolving these conflicting changes becomes a non-trivial challenge.
- Developer Burden: Application logic must be designed to tolerate and gracefully handle inconsistencies and eventual convergence.
When Eventual Consistency Makes Sense
Eventual consistency is appropriate for read-heavy workloads and scenarios where temporary inconsistencies are acceptable. Common examples include:
- Social media feeds
- Shopping cart updates
- Notification services
- Analytics dashboards
- Large-scale IoT applications
Even in critical applications, eventual consistency can be used selectively. For instance, a messaging platform might apply eventual consistency for message reactions or read receipts—where temporary inconsistency is tolerable—but use strong consistency for edits, deletions, and identity data.
Eventual Consistency in Concurrent Write Scenarios
Unlike strong consistency models, which often require write operations to be serialized or routed through a primary node, eventual consistency allows concurrent writes across different regions without immediate coordination. This improves system throughput and reduces write latency.
However, this benefit introduces data reconciliation complexity:
- Techniques such as last-write-wins (LWW), merge functions, or vector clocks may be used to resolve write conflicts.
- These techniques can lead to data loss or non-deterministic outcomes if not handled properly.
The Power and Pitfalls of Eventual Consistency
Eventual consistency is a pragmatic model that embraces the realities of distributed systems: network partitions, regional failures, and high-scale demand. By allowing temporary divergence in data views, it provides systems with resilience, availability, and speed—which are often more valuable than perfect synchronization in real-time.
However, it requires thoughtful design:
- Identify which data and operations can tolerate eventual convergence.
- Implement robust conflict resolution and data validation strategies.
- Ensure transparency with users where temporary inconsistency may be visible.
Ultimately, eventual consistency offers operational flexibility in a global landscape, but it must be wielded carefully—balancing user experience, correctness, and system performance.
Causal Consistency: Preserving the Sequence of Events in Distributed Systems
Causal consistency is a powerful and intuitive consistency model used in distributed systems to ensure that operations which are causally related are seen by all nodes and users in the same order. Unlike strong consistency, it does not guarantee that all operations are seen in the same order — only those that are causally linked. This strikes a valuable balance between usability and system performance, especially in collaborative or interactive applications.
Understanding Causal Relationships
To understand causal consistency, let’s consider a messaging application with support for threaded conversations and replies:
- User A posts a message.
- User B replies to that message.
- User C then replies to User B’s comment.
Here, there’s a causal chain of actions: A → B → C. If User D accesses the conversation from another region, causal consistency ensures that this user sees the original message, then B’s reply, and finally C’s reply — in the same causally derived order. If this sequence is disrupted (e.g., C appears before A or B), it can cause confusion or misinterpretation of context.
Causal consistency preserves the natural flow of conversations and interrelated events — a critical requirement for systems where the meaning of an action depends on previous actions.
Why Causal Consistency Matters
In real-time systems like:
- Messaging platforms
- Collaboration tools (e.g., Google Docs, Notion)
- Multiplayer games
- Social media threads
- Event-sourced systems
…the ordering of actions is as important as the actions themselves. Misordered events can result in:
- Incorrect business logic execution
- Broken user experiences
- Inconsistent application states
Causal consistency ensures that users always see related actions in the correct temporal and logical sequence, regardless of where they are or what node they’re connected to.
How Causal Consistency is Implemented
Implementing causal consistency is technically complex. Distributed systems must track the causal relationships between operations, even when executed across different regions, data centers, or availability zones. Several techniques help achieve this:
1. Vector Clocks
A vector clock is a list of counters, one per process or node, used to record the number of operations performed by each process. It enables nodes to determine the causal relationship between two events — whether one happened-before, happened-after, or happened concurrently.
Each operation carries a vector timestamp, and comparing these timestamps allows the system to enforce proper event ordering when replicating or displaying data.
2. Lamport Timestamps (Logical Clocks)
Lamport clocks assign a scalar timestamp to each operation and are easier to implement than vector clocks. However, they cannot capture concurrency — they only indicate a total ordering, not causal dependencies. This makes them suitable for certain use cases where approximate order is acceptable, but not sufficient for true causal consistency.
3. Dependency Tracking
Some systems explicitly encode which events depend on which other events. This dependency information is used to defer the application of an event until all its prerequisites are available.
4. Quorum and Consensus Mechanisms
Some quorum-based systems (e.g., those built on Raft or Paxos) enforce ordering through distributed commit logs or operation queues, ensuring that causally related writes are acknowledged in proper order.
Causal Consistency vs Other Models
| Consistency Model | Guarantees | Performance | Use Case |
|---|---|---|---|
| Strong | Global agreement on latest value | Low latency | Banking, inventory, transactional apps |
| Eventual | Data converges eventually | High | Social feeds, analytics |
| Causal | Preserves order of related updates | Medium | Messaging, collaboration tools |
Causal consistency represents a middle ground between strong and eventual consistency:
- It improves on eventual consistency by ensuring that causally related updates are not seen out of order.
- It relaxes strong consistency to allow better performance and availability without compromising logical coherence.
Practical Example: Messaging Reply Threads
Let’s return to the example of a threaded messaging service:
- If causal consistency is not enforced, replies might appear before the original message.
- Worse, a response to a reply might appear before the reply itself, confusing users and fragmenting the thread.
With causal consistency:
- Replies follow the messages they reference.
- Edits to a reply will not show up until the original message and prior replies are also present.
- Users experience a logical narrative flow of events, even in a globally distributed architecture.
Where Logic Meets Latency
Causal consistency ensures that related operations are always processed and presented in the correct order, which is essential for any user-facing system where sequence implies meaning. By enforcing causality, systems can provide clear, predictable behavior, improve user trust, and avoid logical contradictions — without the global coordination overhead required by strong consistency.
However, implementing causal consistency requires thoughtful engineering and trade-offs:
- Additional metadata (e.g., vector clocks) increases payload size.
- Storage and compute costs may rise slightly.
- Latency for displaying dependent events may increase if dependencies aren’t yet available.
Yet for many applications, these are reasonable trade-offs for the benefits of logical consistency and user experience coherence. In today’s world of real-time collaboration and globally connected platforms, causal consistency is no longer optional — it’s essential.
Read-Your-Writes Consistency: Ensuring Immediate Feedback in Distributed Systems
Read-your-writes consistency is a fundamental consistency model that ensures a user can immediately read back their own updates after a write operation. This model is critical for maintaining a coherent user experience in any interactive system where users expect to see the result of their actions in real-time.
In other words, once a user submits or modifies data, any subsequent read they perform should reflect those changes — regardless of which server or database node handles the request. This feedback loop builds trust, minimizes confusion, and reduces redundant user actions.
Why Isn’t It Always Guaranteed?
At first glance, it may seem intuitive that a user should always see their most recent updates. However, in distributed or replicated database architectures — especially master-replica setups — this isn’t always the case.
Understanding Master-Replica Architecture
In a typical master-replica database configuration:
- Writes are directed to the master node (also known as the primary).
- Reads are distributed across replica nodes (also called secondaries) to reduce load and improve response time.
After a write operation occurs on the master node, the change is replicated to one or more replicas. This replication can happen:
- Synchronously: The master waits for replicas to confirm receipt of the write.
- Asynchronously: The master immediately confirms the write and updates replicas later.
Asynchronous replication introduces replication lag — a time window during which replicas may still hold stale data. If a user performs a read operation during this lag and the request is routed to a replica, they may not see the results of their own write. This can lead to inconsistent application behavior and user confusion.
The Role of Read-Your-Writes Consistency
With read-your-writes consistency, the system guarantees that once a write is acknowledged, any subsequent read by the same user reflects that write — no matter where the read request is served from.
To achieve this, systems may adopt several strategies:
-
Session Stickiness (Read-after-Write Routing)
After a write, subsequent reads from the same user or session are routed to the master node or a replica that has acknowledged the write. -
Synchronous Replication
The system waits until all relevant replicas have been updated before acknowledging the write. This ensures any read routed to those replicas returns up-to-date information.
Downside: This increases write latency since the operation isn’t considered successful until replication completes. -
Hybrid Approaches
Some systems use intelligent caching or metadata to determine the freshest replica or fail over to the master for critical reads.
Practical Example: Messaging Application
Consider a messaging app with a read-your-writes consistency requirement. Here are a few user interactions that highlight its importance:
- Editing Messages: A user edits a message. Without read-your-writes consistency, they may still see the old version of their message, causing confusion or triggering repeated edit attempts.
- Joining Channels: A user joins a channel and expects to see it listed in their sidebar. Without immediate feedback, the user may believe the operation failed.
- Profile Updates: Users updating their status or profile picture expect to see the changes reflected immediately, reinforcing a seamless experience.
If this feedback loop is broken, users may:
- Re-submit actions.
- Assume their changes failed.
- Report phantom bugs or errors.
- Lose trust in system reliability.
Trade-Offs and Design Considerations
While read-your-writes consistency greatly improves user experience, it does introduce trade-offs:
| Trade-Off | Description |
|---|---|
| Latency vs. Consistency | Ensuring strong consistency across all replicas before acknowledging a write can increase response latency. |
| Load on Master Node | Routing all post-write reads to the master can increase the load and reduce scalability. |
| Complexity in Routing | Session-aware routing logic needs to be implemented to ensure consistency across distributed environments. |
Engineers must assess the nature of the application and weigh:
- How critical immediate read-after-write feedback is.
- Tolerance for added latency.
- Availability of infrastructure to support synchronous updates or intelligent routing.
Visibility Drives Trust
Read-your-writes consistency is not just a technical detail — it’s a trust-building mechanism. It ensures that users experience the system as responsive, reliable, and deterministic. Especially in user-centric applications like messaging platforms, collaborative editors, banking apps, and social networks, this consistency model is essential.
By carefully balancing replication strategies and architectural patterns, organizations can implement read-your-writes consistency in a way that optimizes both user experience and system performance.
When users see their updates immediately, they feel confident. And in distributed systems, that feeling of confidence is one of the most valuable currencies you can earn.
Monotonic Reads Consistency: Guaranteeing Forward Progress in Distributed Systems
Monotonic read consistency is a key consistency model that ensures users never “go back in time” when reading data in distributed systems. Once a user reads a particular version of an entity or object, they are guaranteed to either see that same version or a newer one on subsequent reads — never an older or stale version.
This property is vital in user-facing applications where backward inconsistencies can lead to confusion, poor user experience, or incorrect assumptions about the system’s behavior.
The Core Principle
In distributed systems with eventual or asynchronous replication, it’s possible for read operations to retrieve different versions of the same data — sometimes even older versions than what the user has previously seen. Monotonic reads consistency prevents this by preserving a minimum version threshold per user session.
Once a user sees a particular state of the data, all future reads for that user will respect that version or something more recent. This consistency model does not guarantee global ordering, but ensures session-level forward progress.
Real-World Analogy: Messaging Application
Consider a messaging app used across multiple devices and global regions. A user opens a conversation on their laptop and reads the latest messages in a group chat. If the same user then switches to their mobile device:
- Without monotonic reads: Their mobile app may fetch messages from a replica that hasn’t yet received the latest updates. This could cause some previously seen messages to disappear or appear in an outdated form.
- With monotonic reads: The mobile app will only retrieve messages that are at least as recent as those already viewed on the laptop. This ensures continuity and prevents the user from seeing an outdated or incomplete view of the conversation.
This consistency model is particularly valuable in:
- Feed-based applications (e.g., social media, messaging apps)
- Financial dashboards (e.g., portfolio updates, balance changes)
- Inventory tracking (e.g., product availability in e-commerce platforms)
Practical Implementation Considerations
To support monotonic reads, systems typically need:
-
Session Tracking or Version Metadata
Each client session is associated with metadata (e.g., timestamps, vector clocks, or version vectors) representing the latest data state seen by the user. -
Replica Selection Logic
Read operations are routed to replicas that can serve data at least as fresh as the client has previously seen. -
Read Repair or Retry Mechanisms
If no replica meets the freshness threshold, the system may:- Retry the read after replication completes.
- Route the request to the primary or a more up-to-date replica.
- Delay the response until a suitable replica is found.
These measures ensure users do not observe inconsistent or regressive data states, even when replication lag exists across nodes.
Applying to Message Deletions and Updates
Let’s revisit our messaging service use case.
- A user views a message at timestamp T1.
- Later, that message is deleted or edited at timestamp T2.
- If the user issues another read request at timestamp T3, monotonic read consistency guarantees that:
- The original message will not reappear.
- Only the updated (edited or deleted) version of the message will be shown.
This eliminates confusing behaviors like:
- Deleted messages reappearing temporarily
- Seeing an outdated version of a message after already seeing the edited one
- Fluctuating message states depending on which replica the user’s request hit
Benefits and Trade-Offs
| Benefits | Trade-Offs |
|---|---|
| Predictable and consistent user experience | Slight increase in read latency (replica selection) |
| Avoids regressions in data visibility | Requires session awareness and tracking mechanisms |
| Enables safe cross-device interactions | May not scale easily without robust metadata |
Forward-Only Visibility for Reliable Experiences
Monotonic read consistency provides a subtle but powerful guarantee that reinforces user trust in distributed applications. By ensuring that users always see forward progress — never regressing to outdated data — this model brings clarity and predictability to user interactions.
In an age of multi-device, globally distributed, and real-time applications, preserving this progression is essential to ensure smooth experiences across messaging, commerce, collaboration, and beyond. While monotonic reads may introduce some architectural complexity, the resulting confidence and consistency for users make it a compelling choice in modern system design.
Monotonic Writes Consistency: Ensuring Ordered Commit of User Actions
Monotonic writes consistency guarantees that write operations issued by a user or process are always applied in the order they were issued, regardless of where those writes are processed in a distributed system. This ensures both data correctness and a smooth user experience, especially in scenarios involving rapid or sequential updates.
What It Really Means
In distributed systems, writes can be issued by clients to different replicas, particularly in geographically dispersed cloud regions. Without proper safeguards, these writes could be applied out of order, leading to:
- Inconsistent application state
- Overwritten changes
- Confusing user experiences
Monotonic writes consistency eliminates this risk by ensuring that every successive write from a client is acknowledged only after all previous writes have been successfully propagated and committed.
Real-World Example: Messaging Application
Let’s apply this concept to a messaging channel scenario:
A user edits a message three times in a row within a few seconds:
- Edit 1: “Let’s meet at 3pm”
- Edit 2: “Let’s meet at 2pm”
- Edit 3: “Let’s meet at 2:30pm”
Without monotonic write consistency, there’s a risk that due to network latency, these edits could be applied in the wrong order. For example, the last visible version might read “Let’s meet at 3pm” — an outdated value — because Edit 1 was applied after Edit 3 at one replica.
With monotonic writes consistency, the edits are committed and observed in the correct chronological order. The final visible message will always reflect the latest intended version: “Let’s meet at 2:30pm”.
How Is It Enforced?
Systems ensure monotonic write consistency through several mechanisms:
- Session-based sequencing: Maintaining a session or transaction ID that tracks the order of client-issued operations.
- Write acknowledgments: Ensuring a write is only accepted once prior writes are fully committed.
- Vector clocks / Lamport timestamps: Capturing causal relationships and sequencing information in write operations.
- Quorum writes: Using majority consensus to ensure updates are durable and consistently ordered.
These techniques prevent scenarios where newer writes are overwritten by older ones due to asynchronous replication or race conditions between geographically distributed nodes.
Monotonic Writes vs. Causal Consistency
At first glance, monotonic writes and causal consistency may seem similar — both preserve operation order. However, the scope and guarantees differ:
| Feature | Monotonic Writes | Causal Consistency |
|---|---|---|
| Guarantees | Order of writes from a single client is preserved | Order of related operations (writes and reads) is preserved |
| Scope | Write-only sequencing | Read-after-write and write-after-read dependencies |
| Typical Use Case | Sequential updates by one actor | Collaborative systems where reads influence future writes |
| Enforcement Complexity | Lower (focused on sequencing per writer) | Higher (tracks relationships across sessions and users) |
So while causal consistency implies monotonic writes, monotonic writes does not necessarily imply full causal consistency.
Benefits of Monotonic Writes
- Consistency in user experience: Users never see an outdated or jumbled view of their own updates.
- Data correctness: Prevents lost updates and write conflicts.
- Simplicity: Especially useful in single-writer models, session-based workflows, and edge-device scenarios.
Write with Confidence
Monotonic writes consistency is foundational for any distributed system where preserving the user’s intent is critical. By ensuring write operations are applied in the order they were issued, this consistency model protects the integrity of user updates and avoids confusing or erroneous application behavior.
In fast-paced applications like messaging, collaborative editing, or real-time dashboards, enforcing monotonic writes provides clarity, trust, and correctness — forming an essential building block in the design of reliable distributed systems.
Understanding the Difference Between Monotonic Read-Write and Causal Consistency
At first glance, monotonic read-write consistency and causal consistency may seem similar — both preserve the order of operations. However, they differ fundamentally in scope and intent.
Let’s break this down with a narrative example that illustrates the key distinction between the two consistency models.
A Conversation in a Group Chat
Imagine a group chat with two users: Alex and Taylor. They’re both messaging in the same shared channel on a globally distributed messaging platform.
Scenario 1: Monotonic Read-Write Consistency (Focused on One User)
Alex types out and sends three messages:
- “A: Hey everyone!”
- “B: Just got back from vacation.”
- “C: Can’t wait to share pictures.”
With monotonic write consistency, the system ensures that Alex’s own messages appear in order. No matter which data center Alex connects to, and even if there’s a replication delay across regions, Alex will never see their own messages appear out of order — they’ll always appear as A → B → C.
If Alex edits “B” later, then views it again, monotonic read consistency ensures Alex won’t see an older version of “B” — only the latest update or something more recent.
✅ This model is self-consistent: the user’s personal actions always appear in the correct sequence.
❌ But for other users, this consistency model doesn’t make any guarantees.
Scenario 2: Causal Consistency (Cross-User, Cause-and-Effect Aware)
Now let’s introduce Taylor into the conversation.
- Alex posts message A: “Hey everyone!”
- Taylor replies with A1: “Hey Alex, how was the trip?”
- Alex then sends message B: “Just got back from vacation.”
Here, the messages are causally linked:
- A1 is clearly a reply to A.
- B follows naturally after both A and A1.
In a causally consistent system, this cause-and-effect chain is preserved for all users. So, no matter where in the world another user logs in from, they will always see:
A → A1 → B
Why is this important? Because if the messages arrive out of order — say B appears before A1 — the conversation becomes confusing:
A → B → A1
(“Just got back” appears before anyone asked how the trip was.)
With causal consistency, the dependency between events is respected across the entire system. All users see related events in the correct logical sequence, even if unrelated events appear in different orders.
Summary of the Differences
| Feature | Monotonic Read-Write Consistency | Causal Consistency |
|---|---|---|
| Scope | Per-user or single process | System-wide, across users and processes |
| Guarantees | Operation order for reads/writes by one user | Order of causally linked operations across all users |
| Use Case | Ensuring users see their own actions in order | Preserving the logic of conversations or reactions |
| Example | Alex sees messages A → B → C | Everyone sees A → A1 → B in a logical thread |
When to Use Which?
-
Use monotonic consistency when the user experience depends on internal coherence — like editing a document, viewing personal settings, or revisiting your own messages.
-
Use causal consistency when preserving the logic of shared interactions is critical — such as chat replies, collaborative work, or timeline-based discussions where sequence impacts meaning.
In a distributed world where users interact across cloud regions and availability zones, these distinctions aren’t just academic — they shape how users perceive truth and trust in your system. By understanding and applying the right consistency model, architects can deliver both performance and predictability, tailored to the nuances of each user scenario.
Session Consistency: Balancing Local Precision with Global Flexibility
In the realm of distributed systems, session consistency provides a powerful yet pragmatic compromise. It ensures that a user experiences a consistent and ordered view of their own interactions within a single session, while allowing for relaxed consistency guarantees outside of that session scope.
Imagine you’re using a messaging platform like Slack or Discord. You begin a session by logging in and participating in a group chat. As you type and edit messages, your actions unfold in a natural, predictable sequence. This smooth, uninterrupted flow — where your edits reflect immediately and your sent messages appear in the order you intended — is made possible by session consistency.
Local Order, Guaranteed
Session consistency guarantees that within a user’s active session, operations — such as message edits, deletions, or reads — are reflected in the order they were issued. If you edit a message three times in succession, you will always see the edits appear in the correct sequence. You’ll never encounter an earlier version of a message overwriting a later one in your own session.
This kind of consistency is essential for user-centric applications, especially those with high levels of interactivity. Whether it’s chat, collaboration, or real-time dashboards, the user must perceive a coherent experience — one where their actions make immediate, logical sense.
Practical Application in Messaging Platforms
Let’s apply this to a chat system. When you send a flurry of messages or respond to others in a thread, the system may internally assign monotonically increasing sequence numbers or timestamps to your messages. When you retrieve your message history, the application uses these markers to reconstruct the order in which your messages were sent. This provides a reliable, linear conversation flow from your perspective.
However, here’s where session consistency draws a line: it does not guarantee global ordering across users. If several users are participating in a channel, the sequence of messages each person sees might differ slightly. One user may see Bob’s message before Alice’s, while another might see the reverse. This divergence arises from network latencies, message broker behavior, and regional differences in how distributed nodes receive and propagate updates.
Navigating the Trade-offs
While this might seem like a limitation, it’s actually a calculated design trade-off. Enforcing strict global consistency across geographically dispersed users can impose significant latency and complexity. By limiting the consistency guarantee to individual sessions, systems can optimize for responsiveness, performance, and scalability, without sacrificing the individual user’s experience.
In practice, many large-scale systems employ a multi-tiered consistency model, tailoring the level of consistency based on the needs of each use case:
- Strong consistency for critical shared operations (e.g., banking transactions)
- Session consistency for personalized user flows
- Eventual consistency for background syncing or low-impact updates
This approach allows systems to remain both responsive and resilient — a necessity in globally distributed environments where users expect real-time performance regardless of location.
Regional Nuances and Architectural Flexibility
When deploying across cloud regions, session consistency can be particularly useful. Different regions may face varied network conditions, replication lags, or compliance requirements. By scoping consistency guarantees to user sessions, architects can localize complexity and minimize global coordination overhead.
This flexibility empowers engineers to fine-tune system behavior in ways that deliver seamless experiences to end-users while maintaining operational efficiency.
Consistency that Scales with User Intent
Session consistency is not about imposing global order — it’s about honoring the user’s perspective. It prioritizes the integrity of each individual’s experience within a session while giving the system freedom to optimize consistency trade-offs across broader operations.
In distributed architectures where every millisecond matters and global coordination can be costly, session consistency strikes a practical balance. It enables systems to feel real-time and intuitive — even when stitched together across continents — giving users the illusion of seamless coherence, even as the underlying infrastructure embraces complexity.
Navigating the Trade-Offs of Data Consistency
Data consistency is at the heart of distributed system design — it governs how users experience your application, how developers build features, and how businesses uphold trust. As we’ve explored, consistency is not binary; it’s a spectrum with levels that cater to different operational needs, from the strict guarantees of strong consistency to the flexible, scalable nature of eventual and session consistency.
The real power lies in selecting the right consistency level for each context:
- Use strong consistency when correctness and uniformity across regions are non-negotiable — such as in banking, healthcare, or real-time collaboration tools.
- Apply eventual consistency when high availability and fault tolerance outweigh the need for immediate uniformity — like social feeds or chat messages.
- Leverage causal, monotonic, session, and read-your-writes consistency to fine-tune user experience, reduce cognitive dissonance, and ensure coherent interactions within the bounds of performance trade-offs.
The art of distributed architecture lies in balancing these trade-offs to meet service-level expectations while maintaining resilience and scalability. With a thoughtful approach to consistency, organizations can deliver intuitive, performant, and dependable user experiences — even across a complex mesh of cloud regions and data centers.
Ultimately, the consistency model you choose reflects your product’s priorities. As systems grow in complexity and scale, understanding and applying nuanced consistency guarantees becomes not just a technical consideration — but a strategic one.


