
Introduction
Large Language Models (LLMs) are at the forefront of a profound shift in artificial intelligence. Historically, progress in LLMs has been driven by scale—scaling model parameters, expanding dataset sizes, and pouring vast amounts of computational resources into training-time optimization. While this brute-force approach has yielded impressive results, a new wave of innovation is reshaping the landscape: inference-time reasoning.
Rather than relying solely on what was learned during training, modern LLMs are being designed to “think” during inference. This means allocating more compute dynamically at the time of response generation, enabling more sophisticated reasoning, step-by-step deliberation, and problem-solving capabilities. This transformation marks a shift from static knowledge retrieval to active computation—a model reasoning through a problem instead of recalling an answer.
This report explores how reasoning has emerged as a defining competency for next-generation language models. Nowhere is this shift more evident than in mathematics, a domain that demands structured logic, precise derivation, and multi-step inference. As models like DeepSeek-R1-Zero and R1 demonstrate, the ability to reason is no longer a luxury—it’s becoming a core design principle. But before we dive into these innovations, it’s essential to understand the evolution that brought us here—and the strategic implications of transitioning from training-time scale to test-time intelligence.
The Growing Importance of Reasoning in AI
The ability to reason represents a fundamental leap in what AI systems can achieve. Traditional LLMs, while powerful, often functioned as high-capacity pattern matchers—excellent at mimicry, but limited in abstract problem-solving. By contrast, reasoning-capable models go a step further: they can simulate deliberation, validate their own logic, and iterate toward better solutions.
This enhancement unlocks transformative capabilities, including:
- Transparent Problem Solving: Models can now explain not just what they know, but how they arrived at a conclusion, offering step-by-step justifications.
- Self-Evaluation: Through mechanisms like chain-of-thought prompting and scratchpad reasoning, models can reflect on and revise their initial outputs.
- Dynamic Refinement: Reasoning allows iterative improvement, where intermediate outputs can inform subsequent steps—much like how a human revises their thoughts while working through a problem.
These reasoning capabilities are revolutionizing performance in disciplines that demand precision and rigor, such as mathematics and computer science. But their impact extends further—enhancing applications in natural language understanding, legal reasoning, decision support, financial forecasting, and multilingual translation.
In essence, reasoning elevates AI from statistical text generation to a form of structured cognitive computation. This unlocks not only greater accuracy, but also trust, interpretability, and human-like flexibility—qualities that are essential as LLMs become embedded in critical enterprise workflows and real-world decision-making.
What Sets a Reasoning-Capable LLM Apart?
Traditional language models operate by associating inputs with outputs through learned statistical patterns. They aim to generate responses that most likely follow from a given prompt based on their training data. While effective in many cases, this approach lacks the depth needed for solving complex, multi-step problems that require logical progression and inference.
Reasoning LLMs break away from this paradigm. Instead of delivering immediate answers, they decompose problems into a sequence of logical steps, much like a human would when working through a math problem, writing an essay, or debugging a piece of code. This process—known as multi-step inference or chain-of-thought reasoning—enables the model to simulate analytical thinking rather than just producing memorized patterns.
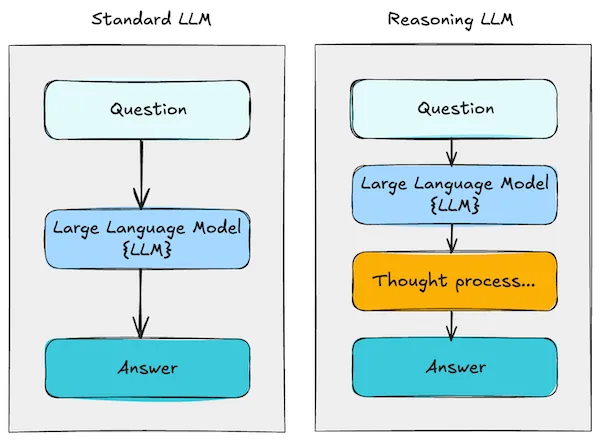
Let’s illustrate this with a geometric problem:
Prompt: “A rectangular garden has a length of 12 meters and a width of 8 meters. If I want to place a diagonal pathway across the garden, how long will the pathway be?”
A conventional LLM might attempt to answer this directly—often correctly, but sometimes with errors due to reasoning shortcuts or hallucinated math.
By contrast, a reasoning LLM would break the problem down into clear, step-by-step inferences:
- “The garden is a rectangle with a length of 12 meters and a width of 8 meters.”
- “A diagonal pathway crosses from one corner to the opposite corner.”
- “This forms a right triangle, with the diagonal as the hypotenuse.”
- “Apply the Pythagorean theorem: hypotenuse² = 12² + 8².”
- “hypotenuse² = 144 + 64 = 208.”
- “hypotenuse = √208 ≈ 14.42 meters.”
- Final Answer: “The diagonal pathway will be approximately 14.42 meters long.”
This structured decomposition brings several key benefits:
- Transparency: Each reasoning step can be reviewed and understood independently, making the model’s logic interpretable.
- Error Correction: Mistakes in one step can be isolated and corrected without invalidating the entire response.
- Generalization: By internalizing logic over memorized facts, the model can better handle novel problems and contexts.
Ultimately, reasoning LLMs aren’t just more accurate—they are more trustworthy, explainable, and aligned with human cognitive expectations. This makes them invaluable not just for STEM domains, but also for applications in legal reasoning, enterprise decision-making, and any task where logic must be both sound and visible.
Train-Time Compute: The Traditional Paradigm
In the foundational era of large language models (LLMs), most performance improvements were driven by a straightforward formula: scale everything. This train-time compute paradigm focused heavily on enhancing model capabilities before deployment, during the pre-training phase. The dominant strategy involved scaling three fundamental levers:
- Model Size – Measured by the number of parameters (e.g., GPT-3’s 175B parameters). Larger models generally captured more nuanced language patterns and exhibited stronger generalization.
- Dataset Size – Expanding the total number of training tokens allowed models to observe more diverse language structures and contexts.
- Compute Power – Leveraging more floating-point operations per second (FLOPs) enabled longer and more frequent updates to model weights, improving convergence and robustness.
This approach is grounded in well-known scaling laws, such as:
- Kaplan’s Scaling Law – Which suggests that, under a fixed compute budget, increasing model size yields the greatest returns up to a point.
- Chinchilla Scaling Law – Which adjusts the balance, showing that smaller models trained on more data can outperform larger ones with insufficient data, emphasizing that both data quantity and model capacity must be scaled in tandem.
While these laws helped guide a decade of progress in LLM design, diminishing returns have become increasingly apparent:
- Larger models require exponentially more compute, leading to high infrastructure costs and environmental concerns.
- Improvements from brute-force scaling become marginal at high parameter counts.
- The models often fail to learn how to reason—opting instead to memorize training patterns without true comprehension or adaptability.
As a result, the AI community is gradually shifting away from over-reliance on train-time scaling, and exploring new paradigms that emphasize smarter inference-time strategies—giving rise to the next generation of reasoning-capable LLMs that can adapt and think at the time of use, not just during training.
This shift represents a paradigm evolution—from models that are passively pre-trained to those that engage in active reasoning during inference, enabling more dynamic, transparent, and flexible performance in real-world applications.
Test-Time Compute: Thinking at the Moment of Inference
Test-time compute marks a fundamental evolution in how large language models (LLMs) process and deliver answers. Unlike the traditional paradigm where all intelligence is “baked in” during training, this approach allocates additional computation at inference time — enabling models to “think” more deeply before finalizing a response.
Rather than responding instantly with a predicted output, reasoning-oriented LLMs engage in multi-step cognitive processes during inference. These intermediate steps are not just artifacts — they are essential tokens of thought that represent how the model arrives at a conclusion.
Consider a simple prompt:
“What is the square root of 169?”
-
A standard LLM trained with conventional methods might answer directly:
“13” -
A reasoning LLM leveraging test-time compute might elaborate:
“To find the square root of 324, I need to identify a number that, when multiplied by itself, equals 324.
18 × 18 = 324
Therefore, the square root of 324 is 18.”
While both models produce the same result, the latter approach mirrors human problem-solving more closely, offering transparency, traceability, and the potential for self-correction at each reasoning step.
In more complex domains such as mathematics, scientific reasoning, or legal analysis, these chains of thought can span dozens or hundreds of tokens, allowing the model to:
- Explore multiple reasoning paths in parallel
- Compare and refine hypotheses
- Backtrack and correct faulty logic
- Justify its conclusion in a structured way
This dynamic and deliberate computation makes reasoning LLMs far more robust in handling edge cases, ambiguous inputs, or problems requiring logical derivation.
Moreover, test-time compute decouples performance from model size alone, meaning that even smaller models — if given sufficient inferential steps — can outperform massive, purely training-time-optimized systems on complex tasks.
In essence, test-time compute gives rise to adaptive intelligence: instead of memorizing solutions, the model actively constructs them in real-time. This not only enhances reasoning performance but also offers a pathway to explainability, auditability, and trust — key requirements for AI adoption in enterprise, education, healthcare, and governance.
Scaling Test‑Time Compute
The concept of scaling test-time compute represents a groundbreaking evolution in the field of AI reasoning. Traditionally, performance improvements in LLMs were primarily driven by scaling up training-time compute—increasing model size, expanding datasets, and consuming more FLOPs during pre-training. However, recent advancements suggest that allocating more computation during inference—known as test-time compute—can deliver comparable or even superior performance improvements, especially in reasoning-intensive tasks.
Inspired by pioneering systems like AlphaZero, which relies heavily on inference-time planning rather than brute-force memorization, researchers have begun to explore how extended chains of thought during inference can lead to significantly better outcomes. These additional computational steps allow models to engage in a deeper and more deliberate problem-solving process, akin to human reasoning.
As test-time computation scales similarly to training-time compute, a new paradigm of “inference-based intelligence” is emerging. These models do not rely solely on pre-trained knowledge or fine-tuned representations. Instead, they strike a strategic balance between training and inference, using the latter to simulate deeper cognitive processing at the moment of decision-making.
This shift reflects the realization that reasoning isn’t just a product of scale—it’s a process. Increasing the number of inference steps effectively grants the model more “think time,” allowing it to:
- Generate multiple candidate answers
- Evaluate intermediate reasoning paths
- Select the most consistent or valid conclusion
- Self-correct through verification and reflection
These capabilities mirror how humans often solve problems: by iterating, reflecting, and refining thoughts before arriving at a conclusion.
As models become increasingly adept at utilizing test-time resources, they also introduce new opportunities and challenges in deployment. More compute during inference means higher costs and latency—but it also unlocks transformative capabilities in domains that require accuracy, justification, and trust.
With this foundation in place, we now turn to the specific techniques that make extended inference computation effective. In the next section, we’ll explore two core categories: (1) candidate generation and verification, and (2) modifying token proposal distributions to guide reasoning. These techniques sit at the heart of the reasoning revolution, propelling LLMs far beyond their pattern-matching predecessors.
Understanding the Types of Test‑Time Computation in Language Models
As large language models (LLMs) continue to demonstrate impressive capabilities across tasks ranging from summarization to problem-solving, a growing area of focus lies in enhancing their performance during test-time computation—that is, improving how they reason and produce answers at inference time, even after training is complete.
Unlike traditional training approaches, test-time computation strategies do not modify the model’s weights. Instead, they guide how the model generates, evaluates, or selects outputs in real-time. These techniques can significantly improve performance on complex, multi-step tasks by refining either the output generation process or the input distribution and sampling behavior.
Among these innovations is a particularly notable method called the Self‑Taught Reasoner (STaR). STaR improves reasoning quality by rewarding the model not just for getting the right answer but for showing coherent intermediate steps, which fine-tunes how tokens are selected. We’ll explore STaR in depth shortly, followed by its variants such as Quiet-STaR, Q_, and rStar, all of which contribute distinct techniques to improve logical reasoning during inference.
But first, let’s establish the broader categories that these methods fall into:
Types of Test‑Time Calculations
Test-time reasoning strategies can largely be grouped into two major categories:
1. Search Against Verifiers — Focus on Output
This class of methods begins by generating multiple reasoning paths or answers and then evaluating each to determine which is most valid. The structure typically involves three core steps:
- Generation: The LLM produces a set of thought/answer pairs. Each pair contains both the reasoning steps and the final answer.
- Evaluation: Each candidate is assessed by a verifier. This verifier is typically one of two types:
- Outcome Reward Models (ORM): These models score only the final answer’s correctness, without regard for how the answer was derived.
- Process Reward Models (PRM): These go further by assessing how the model arrived at the answer, rewarding structured and logical reasoning.
- Selection: The system selects the most compelling answer using methods like:
- Majority Voting
- Best‑of‑N Sampling
- Beam Search, particularly when leveraging PRMs to prioritize high-quality reasoning.
This technique treats the LLM like a brainstormer—generating multiple ideas, then relying on a secondary system to choose the best one.
2. Modifying the Proposal Distribution — Focus on Input
In contrast to searching among multiple final outputs, this approach focuses on improving the reasoning quality during generation itself. It actively modifies the model’s token distribution at inference time, influencing which tokens the model chooses based on how well they support good reasoning.
Let’s break it down:
- Imagine a distribution of possible next tokens for a given prompt. Traditional models choose the most probable token at each step. But less probable tokens might lead to better reasoning.
- By adjusting the proposal distribution, we bias the model to pick inference-enhancing tokens—even if they aren’t the highest probability under normal conditions.
This strategy can be implemented in two primary ways:
- Prompt Engineering: By carefully designing prompts, we can guide the model’s reasoning behavior explicitly. This can involve instructions like “explain your steps” or “reason through this slowly.”
- Model Training with Reasoning Feedback: For example, in STaR, even if the final answer is already correct, the model is further rewarded for producing a logical reasoning path. This feedback helps it learn to prefer tokens that build clear, step-by-step arguments.
This approach helps the model become a better reasoner—not just by evaluating its outputs, but by restructuring its decision-making process at the token level.
Integrating Both Strategies for Better Inference
The real power emerges when both strategies—searching across outputs and modifying generation behavior—are combined.
For instance:
- You might use prompt engineering or STaR-style training to encourage better intermediate reasoning steps.
- Then, once a few candidates are generated, apply a process reward model to choose the best one.
This dual-layered approach mirrors how humans reason:
- We think through a problem with logical steps.
- We review our answers and select the most coherent one.
It also allows models to become more transparent and trustworthy—qualities that are critical as LLMs are deployed in high-stakes, decision-making environments.
Laying the Groundwork for Better Reasoning
As we stand at the frontier of AI reasoning, test-time computation offers one of the most promising paths forward. These techniques represent more than clever tricks—they are fundamental shifts in how we engage with language models.
Whether it’s generating diverse answers and verifying them with reward models, or modifying the model’s very sampling behavior to favor better reasoning, these strategies allow us to build systems that don’t just guess well—but think well.
The Multi-Stage Evolution of AI Reasoning
The journey toward sophisticated reasoning in language models is not the result of a single breakthrough, but rather a multi-stage developmental process. Each stage builds upon the last, progressively enhancing the model’s ability to handle complex, multi-step reasoning tasks with increasing precision, transparency, and generalization. Let’s walk through these three critical stages:
Stage 1: Foundational Pre-Training — Building the Linguistic Core
At the heart of any large language model lies an extensive pre-training phase, where the model is exposed to vast quantities of unstructured text data drawn from books, websites, academic papers, and other public sources. During this phase, the model learns the syntax, grammar, semantics, and general patterns of human language.
This stage imparts a wide range of linguistic fluency and factual recall, allowing the model to answer straightforward questions, complete sentences, and mimic natural human conversation. However, while this pattern-matching ability is formidable, it lacks structured reasoning—the kind of logical, stepwise problem-solving required for domains like mathematics, scientific deduction, or multi-hop reasoning across documents.
In essence, pre-training lays the groundwork, but it does not endow the model with deep cognition or the ability to reason abstractly. This shortcoming sets the stage for the next evolution.
Stage 2: Specialized Training — Bridging the Reasoning Gap
Recognizing the limitations of raw pre-training, researchers introduced specialized training strategies to refine the model’s internal reasoning pathways. These methods target the development of more deliberate, logical thinking processes.
Three major approaches define this intermediate stage:
-
Chain-of-Thought Learning: This method trains models using annotated examples that include not just final answers, but also the intermediate reasoning steps. These “thought chains” guide the model to mimic structured reasoning patterns, much like a student showing their work in math class.
-
Candidate Generation with Reward: Instead of forcing the model to follow a specific path, this technique encourages exploration. It generates multiple answer candidates and rewards correct final outcomes, regardless of how the model reached them. This allows the model to discover alternative, valid reasoning paths on its own.
-
Dynamic Training Loops: Rather than relying on static datasets, dynamic training incorporates continual feedback and evolving data, fine-tuning the model in response to performance on reasoning tasks. It adapts in real-time, mirroring how human learners adjust their understanding based on mistakes and feedback.
Together, these techniques serve as a cognitive apprenticeship, teaching the model not just what to think—but how to think in structured, goal-oriented ways.
Stage 3: Advanced Reasoning Techniques — Refinement and Self-Improvement
Once a model has learned to reason in a structured fashion, the next frontier involves making that reasoning more robust, adaptive, and autonomous. Several cutting-edge techniques are driving this stage of advancement:
-
Self-Taught Reasoner (STaR): A self-improving system where the model iteratively revises and refines its own reasoning steps. Even if the final answer is correct, the model is trained to continue improving the clarity and coherence of its intermediate thought process. It effectively becomes its own tutor.
-
Quiet-STaR: An enhancement of STaR that brings the focus down to the token level, encouraging the model to carefully select each next word or symbol with attention to the logic behind it. This introduces fine-grained control over reasoning trajectories.
-
Q*: A more structured, decision-theoretic approach that treats reasoning as a series of state-action pairs, borrowing ideas from reinforcement learning. Each step in the reasoning chain is evaluated by a utility function, encouraging efficient and correct navigation through problem space.
-
rStar: A method that uses Monte Carlo Tree Search (MCTS) to simulate and evaluate multiple reasoning paths before committing to an answer. It models reasoning as a search tree, exploring branches to find the most promising sequence of thoughts.
Each of these techniques brings something unique: STaR enhances introspective refinement, Quiet-STaR brings precision, Q* adds structure and decision logic, and rStar introduces strategic exploration of solution paths.
The Synergy of Integration
What makes this multi-stage journey powerful is how these layers work in unison. Pre-training builds the language foundation. Specialized training introduces structured reasoning. And advanced techniques like STaR, Quiet-STaR, Q*, and rStar transform reasoning into a dynamic, self-correcting, and transparent process.
Researchers are now actively working on ways to combine these strategies—merging self-taught rationale improvement with tree-based search or reinforcement frameworks—to push reasoning abilities even further.
This holistic evolution is what’s enabling modern AI systems to tackle problems that once seemed out of reach, from theorem proving and complex mathematics to nuanced legal reasoning and multi-document synthesis.
The Road Ahead for AI Reasoning
The development of reasoning in AI is more than a technical pursuit—it’s a philosophical leap toward models that can think with clarity, justify their logic, and learn autonomously. By breaking down reasoning into stages, from foundational language learning to introspective self-guided improvement, we’re getting closer to building machines that reason more like humans.
As these systems continue to evolve, their applications will grow from narrow task-solvers to broad-domain cognitive collaborators, capable of assisting in education, medicine, science, and beyond.
Understanding and leveraging this multi-stage framework is essential—not just for improving performance, but for ensuring the reasoning remains transparent, controllable, and aligned with human values.
The future of artificial intelligence isn’t just about answering correctly—it’s about reasoning responsibly.
Key Techniques Advancing the Reasoning Capabilities of Language Models
Expanding upon this shift toward more thoughtful, inference-aware AI, researchers have introduced a suite of cutting-edge techniques aimed at elevating the reasoning abilities of language models. These innovations are primarily focused on how models process and refine their outputs at test time, allowing them to tackle more complex, multi-step problems than ever before.
Each technique strategically leverages different facets of test-time computation—some optimize output evaluation and selection, while others reshape the input generation and sampling process. Collectively, these methods fall into two overarching categories, each offering distinct advantages and trade-offs depending on the reasoning task at hand.
Through this lens, we’ll explore how these approaches work and why they represent a significant step forward in making AI systems not just accurate, but explainable, adaptable, and logically coherent.
STaR (Self-Taught Reasoner)
Category: Modifying the Proposal Distribution (Focus on Input)
The Self-Taught Reasoner (STaR) represents a pivotal advancement in enhancing the reasoning capabilities of language models by teaching them to generate and refine their own rationales—without requiring large-scale human-labeled datasets. STaR operates by explicitly modifying the proposal distribution from which the model samples its reasoning steps, allowing it to internalize the process of logical deduction and self-correction during test-time inference.
Rather than relying solely on the correctness of final answers, STaR rewards models for producing coherent and structured reasoning paths, even when the outcome is already accurate. This leads to a more robust understanding of intermediate logical steps and helps avoid spurious or shortcut-based reasoning.
The STaR methodology follows an iterative, feedback-driven training loop:
- The model is trained on question-reasoning-answer triplets, which include both the thought process and the outcome.
- If the model answers correctly, its full reasoning and final output are added to the training data, reinforcing that logic path.
- If the model answers incorrectly, it is presented with the correct answer as a “hint” and prompted to revise its reasoning accordingly.
- This process enables supervised fine-tuning based on both success and failure cases, helping the model learn to reason through errors constructively.
A Concrete Example
Suppose the model is tasked with solving a simple arithmetic problem:
345 + 789
On its first attempt, the model engages in step-by-step addition:
- It starts from the rightmost digits:
5 + 9 = 14, writes down 4, and carries 1 - Next:
4 + 8 + 1 = 13, writes down 3, and carries 1 - Then:
3 + 7 + 1 = 11, writes down 1, carries 1—but makes an error and concludes with 1034
The final answer is incorrect.
STaR then provides the correct answer — 1134 — and prompts the model to re-analyze its logic.
On the second pass:
- 5 + 9 = 14, writes down 4, carries 1
- 4 + 8 + 1 = 13, writes down 3, carries 1
- 3 + 7 + 1 = 11, writes down 1, carries 1, which is finally added as the leftmost digit: 1
- Final answer: 1134
In this way, the model revises not just its outcome but also its internal reasoning steps, learning to avoid carry-over errors in future calculations.
Through repeated cycles of generating, verifying, and refining reasoning, STaR improves the model’s ability to handle tasks like multi-digit arithmetic, commonsense reasoning (CommonsenseQA), and complex benchmarks like GSM8K.
Ultimately, STaR shifts the focus of inference from merely selecting likely answer tokens to actively building logical coherence within each thought step—advancing the model’s capability to “think” its way to correct answers.
Quiet-STaR
Category: Modifying the Proposal Distribution (Focus on Input)
Building upon the foundational concepts introduced by STaR, Quiet-STaR refines the reasoning capabilities of language models by pushing rationalization even deeper — from step-level thought chains to the token level itself. While STaR emphasizes generating and improving entire intermediate reasoning steps as distinct sequences, Quiet-STaR seeks to embed this reasoning within the very process of language generation — token by token.
Rather than simply selecting the most plausible answer or refining an output after the fact, Quiet-STaR enables the model to think internally as it composes each token. The model maintains a kind of silent, reflective process — hence the term “quiet” — which continuously guides token generation toward more reasoned and contextually appropriate completions.
This technique relies on a multi-component architecture:
- Internal Thinking Tokens: Special tokens are used to signal when the model should enter a “thinking” state. These tokens guide the model to momentarily pause and consider rationale internally before committing to the next token in a sequence.
- Mixing Head Mechanism: A dedicated mixing head integrates the token-level rationale output with the base language model’s normal token predictions. This blended output balances the model’s linguistic fluency with its internal logical deliberation.
- Reinforcement Learning with REINFORCE-style Updates: Quiet-STaR incorporates a reinforcement learning algorithm to adjust model parameters based on the quality of its rationale tokens. Beneficial reasoning is rewarded, thereby encouraging more useful intermediate logic in future generations.
A Concrete Example
To illustrate the elegance of this approach, consider the sentence prompt:
“The cat sat on the…”
In a traditional model, the next token might be generated simply by selecting the most probable word — say “sofa.” While linguistically valid, this might lack alignment with typical usage in children’s literature or colloquial speech, where “mat” is more expected.
Quiet-STaR, during its internal reasoning phase, evaluates candidate words such as “mat,” “rug,” “sofa,” and more. Initially, it outputs “sofa,” but after receiving subtle contextual feedback — potentially derived from reinforcement learning signals or prior training experience — the model reprocesses its rationale. It updates internal token scores and shifts its token prediction to “mat”, refining the output with a more contextually appropriate completion.
This refinement doesn’t just occur once but is repeated throughout the generation process, ensuring that the entire sentence — and potentially full paragraphs — are composed with continuous internal consistency and logical progression.
By embedding rationales directly into token generation, Quiet-STaR achieves a smooth integration of inference and language modeling. This leads to more natural, contextually intelligent outputs, particularly in longer or more complex tasks like story generation, multi-hop reasoning, and abstract problem-solving.
How do models like STaR and Quiet-STaR contribute to enhancing reasoning abilities?
STaR teaches models to revisit and refine intermediate thought steps after seeing whether the answer was correct or not, effectively learning from its own mistakes and successes. Quiet-STaR takes this further by embedding reasoning into each token, enabling ongoing introspection during the generation process. Together, they transform static inference into a dynamic, introspective reasoning loop — making the model a more thoughtful and reliable problem-solver.
Q* (Q-Star)
Category: Search Against Verifiers (Focus on Output)
The Q* method introduces a highly structured framework for enhancing multi-step reasoning in language models by borrowing principles from classical decision-making frameworks. Rather than modifying the model’s internal generation process (as in STaR and Quiet-STaR), Q* shifts focus to evaluating a diverse set of potential outputs using a learned value function. This positions it squarely in the category of output-verifier-based methods, where the aim is to identify and select the most promising reasoning paths after they’ve been generated.
At its core, Q* frames the reasoning process as a Markov Decision Process (MDP) — a mathematical model frequently used in reinforcement learning. In this context, each step of reasoning is treated as a state-action pair, enabling the model to not just guess the next step, but evaluate its future potential.
In the Q* framework:
- State: Includes the full context — the original prompt plus all prior reasoning steps the model has taken so far.
- Action: Represents the next possible reasoning step the model could take.
- Reward: Assigned based on whether the final reasoning sequence leads to a correct answer.
- Q-value Function: A learned estimator that predicts the expected reward of taking a given action in the current state.
- Search Strategy: Inspired by A*-style heuristic search, the model explores possible reasoning paths but quickly prunes those with low Q-values, focusing computational effort on high-potential trajectories.
This process transforms reasoning into a structured search problem, allowing the model to iteratively refine and optimize its thought process — much like how a chess engine explores only the most promising move sequences.
Example: Solving a Quadratic Equation
Imagine the model is given the task:
“Solve x² – 5x + 6 = 0.”
- Initial State: Recognize this as a quadratic equation, identify coefficients: a = 1, b = –5, c = 6.
- First Action: Apply the quadratic formula: x = (–b ± √(b² – 4ac)) / 2a.
- Compute Discriminant: b² – 4ac = 25 – 24 = 1.
- Calculate Solutions: x = (5 ± √1)/2 = 3 and 2.
In a basic pass, the model might jump to the correct solutions but omit critical intermediate details. The Q* framework then evaluates this reasoning path. If clarity or completeness is lacking, it might suggest revisiting each decision point. On the second pass, the model provides richer, more explainable reasoning — clarifying how it identified the type of equation, why it chose the quadratic formula, how each coefficient factored in, and what each intermediate calculation produced. This structured, transparent reasoning not only improves accuracy but builds user trust in the model’s logic.
Why It Matters
Unlike approaches that depend heavily on vast datasets of step-by-step annotated solutions, Q* is trained only on the final correct answers. It learns to backtrack and assign values to intermediate steps that likely lead to the right solution, allowing it to generalize across problem types.
How does the Q* method structure the reasoning process, and why is it important?
Q* models the reasoning process as a sequence of state-action pairs, where each state is the current context and reasoning history, and each action is a proposed next step. By assigning a Q‑value — an estimate of the final outcome’s quality — to each possible action, the model effectively learns to prioritize promising reasoning trajectories. This strategy mirrors A*-like heuristic search, enabling the model to prune unproductive paths and focus on more promising solutions. The result is a more accurate, efficient, and transparent multi-step reasoning capability, especially valuable in math, logic, and other structured problem domains.
rStar and Monte Carlo Tree Search
Category: Search Against Verifiers (Focus on Output)
The rStar method represents a powerful advancement in reasoning strategies for smaller language models, aimed at enhancing their capacity for complex, multi-step problem-solving without requiring significant fine-tuning or model scaling. Falling under the category of output-focused strategies, rStar is unique in its use of Monte Carlo Tree Search (MCTS) — a method traditionally used in game-playing AI — to explore and validate a wide array of reasoning paths.
Whereas input-focused methods like STaR and Quiet-STaR try to optimize how the model reasons during generation, rStar instead prioritizes what reasoning paths are worth keeping after they’ve been generated. This verification-first approach empowers models to correct themselves by probing the logic of their own thinking.
The rStar framework operates in four key stages:
- Thought Expansion: A smaller base language model initiates the process by generating single-step thoughts or decomposed sub-questions from the original task. Each branch of reasoning acts like a node in a growing tree, analogous to MCTS.
- Verification Layer: A separate verifier model evaluates the logical soundness of each reasoning path. This model doesn’t merely look at outcomes but assesses whether the steps themselves make sense.
- Masking & Reconstruction: A unique aspect of rStar is that it randomly masks parts of the reasoning chain and then attempts to reconstruct them. This helps detect internal inconsistencies and logical gaps in the thought process.
- Exploration & Convergence: The system simulates multiple reasoning branches in parallel, evaluating them iteratively before selecting the most consistent and coherent answer across all paths.
Example: Predicting the Next Number in a Sequence
Let’s consider the problem:
“What is the next number in the sequence 2, 4, 8, 16…?”
- In the first iteration, the model observes that each number doubles and proposes 32 as the answer.
- Then, the verifier model steps in. It asks: “What if we remove the step where the model doubles 16 to get 32?”
- The model tries to regenerate the missing step and confirms that doubling is still the only logical progression.
- It also explores other branches — like checking for additive patterns or looking at prime sequences — but finds they don’t align with the data.
- This process of generating, pruning, and verifying helps the model confidently conclude that 32 is indeed the correct next value.
This kind of iterative refinement makes rStar particularly effective at dealing with ambiguity and subtle reasoning errors. Even small models can simulate a deeper, more reliable thought process by outsourcing verification and using logical reconstruction as a quality control mechanism.
Why It Matters
By pairing generation with active verification, rStar enables smaller models to perform like their much larger counterparts on tasks traditionally reserved for more complex architectures. Benchmarks like GSM8K, MATH, SVAMP, and StrategyQA have shown marked improvements with this technique — all while avoiding the expensive and labor-intensive process of retraining or fine-tuning.
What makes rStar stand out in enhancing reasoning for smaller LLMs?
rStar shines by coupling Monte Carlo Tree Search with a dual-model framework. While one model generates step-by-step reasoning paths, a second verifier evaluates and corrects them. Through techniques like masking and reconstruction, it ensures consistency and logic across multiple iterations. This output-focused strategy empowers even resource-efficient models to solve complex problems, bridging the gap between small-scale deployment and large-scale performance.
The Power of Monte Carlo Tree Search in AI Reasoning
Monte Carlo Tree Search (MCTS) has proven to be a remarkably powerful strategy for elevating the reasoning capabilities of AI systems, particularly in domains that demand sequential decision-making and structured, step-by-step problem solving. Originally popularized in game-playing AIs like AlphaGo, MCTS provides a framework that balances exploration (trying new paths) and exploitation (committing to known successful ones), which makes it especially suited for navigating complex reasoning landscapes.
When applied to language models, MCTS introduces a systematic way to simulate multiple reasoning paths, assess their quality, and progressively converge on the most coherent solution. Rather than generating a single answer in a linear fashion, the model branches out — like a tree — exploring various ways to tackle a problem, whether it’s a math question, a logical deduction, or a multi-hop query.
Each branch of this reasoning tree represents a different thought process, and MCTS evaluates these possibilities based on how promising they appear — using simulation and scoring functions. Poorly performing paths are pruned early, allowing the system to focus its resources on high-quality chains of thought. Over time, this leads to more accurate and robust answers.
In the context of AI reasoning, MCTS isn’t just about finding the right answer — it’s about doing so through a transparent, verifiable process that mimics how humans might consider multiple options before arriving at a decision. This makes it invaluable for enhancing both the performance and interpretability of language models tasked with solving multi-step problems.
The Strategic Edge: Key Advantages of Monte Carlo Tree Search
Monte Carlo Tree Search (MCTS) stands out among reasoning techniques due to its unique ability to balance exploration and exploitation, adapt to time constraints, and operate effectively across diverse domains. These qualities make it an exceptional fit for AI applications where reasoning complexity is high and deterministic paths are hard to define.
-
Balanced Exploration: MCTS excels at navigating vast solution spaces by intelligently balancing between exploring new, potentially promising paths and exploiting known high-performing strategies. This makes it especially suitable for problems with many possible intermediate steps and outcomes.
-
Flexibility Under Constraints: One of MCTS’s most practical features is its interruptibility. Since it builds a search tree incrementally, the algorithm can be halted at any point to deliver the best solution found thus far. This capability is invaluable in real-world AI applications where time and compute are limited.
-
Domain Agnostic: Unlike other search strategies that require domain-specific heuristics or handcrafted rules, MCTS relies primarily on simulation. This makes it remarkably adaptable across a wide range of problem types — from logical puzzles to strategic games to mathematical reasoning tasks — without requiring significant reconfiguration.
-
Efficient Parallelization: MCTS lends itself well to parallel computing. Its simulations and tree expansion steps can be distributed across multiple processing units, making it highly scalable and efficient when applied to large-scale reasoning tasks involving many potential solution paths.
Unpacking the MCTS Workflow: How the Algorithm Operates
At its core, MCTS proceeds through four main iterative phases. These steps are continually repeated to refine the decision-making process and build out a tree of reasoning paths:
-
Selection: Starting from the root node, the algorithm traverses the tree by selecting child nodes according to a selection policy — often based on the Upper Confidence Bound (UCB) — to maintain a balance between exploiting high-value paths and exploring uncertain ones.
-
Expansion: When a node with unexplored children is encountered, the tree is expanded by adding one or more child nodes that represent the next possible actions or reasoning steps. These new nodes expand the search space dynamically.
-
Simulation (Rollout): From the newly added node, a simulation is run by generating a random series of actions — essentially fast-forwarding through a hypothetical solution path using a default or heuristic policy. This estimates the potential outcome if that path were followed.
-
Backpropagation: The results from the simulation are then propagated back through the visited nodes, updating their scores and visit counts. This historical data helps guide the next iteration of the search toward the most promising regions of the tree.
In the realm of AI reasoning — especially when applied to language models — MCTS doesn’t just generate answers; it curates thoughtful, step-wise explorations. By simulating, scoring, and refining different reasoning chains, MCTS enables AI to make informed, transparent decisions on complex, multi-step problems. This process not only enhances accuracy but also brings a layer of interpretability and rigor to language model outputs.
Evolving the Frontier: Hybrid MCTS Methods in AI Reasoning
Building on the foundational structure of Monte Carlo Tree Search (MCTS), researchers have introduced hybrid methods that integrate MCTS with other learning and optimization strategies. These adaptations aim to address some of the inherent challenges of standalone MCTS — such as limited self-assessment and difficulty in fine-tuning decision policies — while expanding its effectiveness in complex reasoning tasks.
These hybrid methods underscore the adaptability of MCTS and its potential as a core component in multi-agent reasoning systems, especially when tasked with intricate challenges such as mathematical derivation, logical inference, and code generation.
SR-MCTS: Self-Refine Monte Carlo Tree Search
SR-MCTS (Self-Refine MCTS) enhances traditional MCTS by embedding a self-critique mechanism within the reasoning loop. The process incorporates a pairwise preference reward model, allowing the system to generate multiple reasoning trajectories and then critique and rerank them based on internal preferences.
This iterative refinement helps eliminate suboptimal paths and promotes better solution quality over time. By empowering the model to evaluate and revise its own reasoning outputs, SR-MCTS brings a new level of introspection and reliability to AI decision-making.
MCTSr: Learning from Self-Evaluation
MCTSr takes MCTS further by introducing self-improvement and self-evaluation steps directly into the search pipeline. Rather than treating reasoning as a static process, MCTSr allows the model to reflect on its own choices, identify missteps, and gradually improve performance through iterative learning.
This continuous feedback loop is especially useful in scenarios where ground truth is limited or unavailable, allowing the model to bootstrap better reasoning capabilities from its own experiences.
MCTS + DPO: Direct Preference Optimization
This variant enhances MCTS with Direct Preference Optimization (DPO). During the expansion phase of MCTS, pairwise preferences are collected — essentially identifying which reasoning paths are more effective than others. These preferences are then used to fine-tune the decision policy of the model.
By directly optimizing for preferred reasoning trajectories, this hybrid approach ensures that the model’s future decisions align more closely with successful past outcomes, improving consistency and reducing drift in complex tasks.
Specialized Hybrid Variants
A number of additional hybrid methods have emerged, each tailored to address specific nuances of AI reasoning:
- ReST-MCTS: Focuses on recursive reasoning and structured thought chaining.
- RethinkMCTS: Encourages revisiting and revising previously explored paths for better accuracy.
- CooperativeReasoning (CoRe): Implements agent-based cooperation where different reasoning modules share insights.
- AlphaMath: Adapts AlphaZero-style reinforcement learning with MCTS to tackle mathematical proofs and equations.
- SC-MCTS: Focuses on subgoal conditioning to break large problems into solvable segments.
These variants are often guided by reward signals, verifiers, or domain-specific test feedback, allowing them to fine-tune partial solutions with remarkable efficiency — particularly in high-precision domains like programming and mathematics.
What role does the rStar approach and Monte Carlo Tree Search (MCTS) play in reasoning enhancement?
The rStar framework demonstrates the transformative power of MCTS by applying it to multi-step reasoning in smaller language models. Here, a lightweight model generates potential reasoning paths, while a verifier checks their consistency by masking and reconstructing parts of the thought chain. This dual-model system explores multiple branches before converging on the best path, much like a chess engine evaluating different board positions.
While reasoning in natural language involves a much broader and more ambiguous search space than board games, rStar proves that even partial application of MCTS — combined with verification — can significantly elevate reasoning accuracy. It underscores MCTS’s value not only as a navigator through vast possibility spaces, but also as a means of reinforcing model robustness through structured self-checking.
By blending MCTS with complementary learning techniques, these hybrid approaches push the frontier of what’s possible in AI reasoning, achieving breakthroughs in precision, adaptability, and self-correction. They represent a significant step forward in building more general-purpose, cognitively capable artificial intelligence.
The Bridge to End-to-End Learning
The evolution of AI reasoning has been marked by progressive refinements in how problems are structured, how reasoning is evaluated, and how training data is generated. These innovations—spanning automated data pipelines, flexible evaluation frameworks, and principled reasoning formats—are not merely incremental upgrades. Together, they form a foundational infrastructure that supports the emergence of more unified, end-to-end learning systems.
This shift signifies a departure from earlier, modular paradigms where components such as reasoning generators, validators, and reward models operated in isolation. Instead, we are witnessing a convergence toward systems that integrate these functions into a cohesive, self-sustaining learning loop. The groundwork laid by these infrastructure advances is critical: without them, the leap to full end-to-end reasoning would remain out of reach.
Enter DeepSeek-R1-Zero—a next-generation model that exemplifies this transition. Unlike prior systems heavily dependent on supervised datasets or painstaking fine-tuning, DeepSeek-R1-Zero is driven by pure reinforcement learning, inspired by landmark achievements in AI game-playing. However, what sets it apart is its application of these techniques to open-ended language and reasoning tasks—areas far more ambiguous and complex than structured environments like chess or Go.
But DeepSeek-R1-Zero doesn’t operate in a vacuum. Its capabilities are only made possible because of the robust scaffolding provided by advances in problem encoding, verifier-guided evaluations, and synthetic data generation. These underlying systems serve as both training grounds and feedback engines, allowing the model to explore, fail, adapt, and improve—all within a tightly integrated, autonomous loop.
In this sense, DeepSeek-R1-Zero doesn’t just represent a new model; it marks a paradigm shift. It bridges the gap between modular AI architectures and unified reasoning agents capable of learning directly from environment interactions and minimal human input. The journey to general-purpose reasoning models is still underway, but with this bridge in place, we are now on firm footing to advance far more rapidly than before.
DeepSeek-R1: The Synthesis of a Reasoning Evolution
The recent wave of infrastructure innovations—ranging from problem reformatting and automated rationale generation to sophisticated evaluation mechanisms—has laid the foundation for a new era in AI reasoning. These advances were not merely supporting features; they were enabling technologies, scaffolding the transition toward fully integrated, end-to-end reasoning systems. At the forefront of this transformation stands DeepSeek-R1, a model that doesn’t just build on these developments, but synthesizes them into a cohesive reasoning framework.
DeepSeek-R1 represents a convergence of the two dominant strategies for enhancing reasoning: Search Against Verifiers and Modifying the Proposal Distribution. Rather than choosing between generating better intermediate steps or validating outputs through structured search, DeepSeek-R1 embraces both. It simultaneously modifies how reasoning is generated and how it is validated, achieving a more nuanced, dynamic, and accurate thought process. This hybridization allows the model to not only propose high-quality reasoning paths but also actively filter and refine them—creating a virtuous cycle of generation and verification.
At the root of this capability is its foundational predecessor, DeepSeek-R1-Zero. This earlier iteration marked a paradigm shift in reasoning by applying reinforcement learning in the style of game-playing AI systems—where the model learns by interacting with a reasoning environment, improving through feedback and reward without requiring explicit supervision at every step. DeepSeek-R1 expands on this by incorporating the benefits of test-time computation techniques: dynamic proposal sampling, iterative rationale refinement, and search-based verification.
By unifying these formerly distinct schools of thought within a single, reinforcement learning–driven architecture, DeepSeek-R1 offers a blueprint for the future of language model reasoning. It no longer treats reasoning as a static path from input to answer. Instead, it views reasoning as an evolving dialogue between competing hypotheses, where the model not only proposes but also interrogates its own thoughts—filtering, refining, and reinforcing in real time.
As a result, DeepSeek-R1 doesn’t merely solve problems more accurately—it solves them more intelligently. And as AI continues its march toward human-like cognition, this model’s hybrid, infrastructure-enabled design provides a compelling glimpse into what that future may look like.
DeepSeek-R1-Zero: Reinforcement Learning from First Principles
At the heart of DeepSeek-R1’s evolution lies its foundational precursor, DeepSeek-R1-Zero—a model that radically reimagines how language models can learn to reason. Rather than following the standard path of supervised fine-tuning, DeepSeek-R1-Zero takes a bold departure. It forgoes curated examples, handcrafted rationales, or labeled reasoning chains. Instead, it embraces a pure reinforcement learning paradigm that echoes the transformative principles of AlphaZero in the domain of language and logic.
Built atop the DeepSeek-V3-Base foundation, DeepSeek-R1-Zero trains exclusively on a specialized dataset of “closed-form Answer-Check” problems—questions with deterministic, objective answers. The focus isn’t on mimicking human-generated explanations or adhering to a particular chain-of-thought format. Instead, the model is encouraged to discover its own reasoning pathways, guided only by the correctness of the final answer.
The name “Zero” is not incidental—it reflects a clean-slate learning approach inspired by AlphaZero. Much like AlphaZero learned to master games from scratch through self-play, DeepSeek-R1-Zero learns to reason through repeated trials and reward-driven feedback. The model is not initialized with manually engineered reward functions or labeled intermediate steps. It simply generates a reasoning chain, delivers an answer, and is rewarded based on whether that answer is right or wrong.
This leads to a subtle but important philosophical shift: in this framework, the reasoning chain is not the goal—it is a tool. A means to reach the answer. Even if the rationale is messy, inconsistent, or unpolished, as long as the final outcome is correct, the model is rewarded. This adheres to the powerful maxim underpinning many reinforcement learning breakthroughs: “Reward is enough.”
Of course, reasoning with natural language introduces challenges far more complex than structured games like Go or Chess. While Monte Carlo Tree Search (MCTS) has proven invaluable in those domains, its application in language models is constrained by the combinatorial explosion of possible token sequences. To mitigate this, DeepSeek-R1-Zero employs a simpler, yet surprisingly effective strategy—rule-based reward functions:
- Accuracy Reward — awarded if the final answer is correct.
- Formatting Bonus — given when the model adheres to expected templates for “thought” and “answer” structures.
These lightweight incentives guide the model without needing deep architectural changes or human annotation. The result is a model that learns to reason from experience, not by rote. It internalizes strategies by attempting, failing, receiving feedback, and refining its approach—all while remaining agnostic to how “pretty” or human-like its internal logic appears.
In sum, DeepSeek-R1-Zero represents a profound shift in how we approach reasoning in AI. It reduces reliance on manual supervision, leans into the raw power of trial-and-error learning, and demonstrates that even in the vast, noisy search space of natural language, a well-structured reward is enough to drive intelligent behavior. This philosophy sets the stage for the more advanced hybrid reasoning capabilities that DeepSeek-R1 ultimately delivers.
The Five-Stage Evolution of DeepSeek-R1: From Foundation to Fluent Reasoning
The training journey of DeepSeek-R1 reflects a meticulously designed five-stage process that strategically blends fine-tuning, reinforcement learning, and synthetic data generation to cultivate advanced reasoning abilities in the model. Each stage is crafted to build upon the previous, ensuring both depth in reasoning and fluency in natural language generation.
-
Cold Start Initialization
The process began with a foundational fine-tuning step using DeepSeek-V3-Base. Approximately 8,000 carefully curated high-quality reasoning examples were used to instill essential reasoning capabilities. This early-stage training acted as a primer, avoiding the potential pitfalls of introducing reinforcement learning too early, such as degraded fluency or readability. It gave the model a stable platform from which more complex training could proceed. -
Reinforcement Learning with Reasoning Objectives
With the cold start model in place, the next step introduced reinforcement learning—similar in spirit to the DeepSeek-R1-Zero approach. However, this phase added further sophistication by integrating enhanced reward mechanisms. These additional metrics ensured that the model not only improved in logical reasoning but also maintained high linguistic consistency in the target output language. This dual focus helped balance reasoning depth with expressive clarity. -
Rejection Sampling and Synthetic Data Generation
This stage marked a major leap in dataset scaling. The reinforcement learning model was used to generate a large volume of synthetic reasoning data. However, quality control was paramount. Through the use of rule-based filters and task-specific reward models, researchers sifted through these generated samples—ultimately curating a refined corpus of 600,000 high-quality reasoning examples. This dataset became the backbone for the next phase of model training. -
Comprehensive Supervised Fine-Tuning
To reinforce reasoning while preserving general language competence, the researchers augmented the synthetic corpus with an additional 200,000 non-reasoning examples, yielding a well-rounded dataset of 800,000 training items. This diverse blend allowed DeepSeek-R1 to internalize strong reasoning patterns without sacrificing versatility in broader NLP tasks. The model was fine-tuned again on this dataset, deepening its reasoning abilities while retaining fluency and domain flexibility. -
Reinforcement Learning for Reflective Self-Correction
In the final training stage, reinforcement learning was reintroduced—this time with a clear emphasis on human alignment and clarity. The model was rewarded for generating responses that demonstrated clear, concise reasoning steps aligned with human preferences. These refinements helped the model simplify complex thought processes and present answers in a more accessible and user-friendly format.
A key distinction that sets DeepSeek-R1 apart from other reasoning-enhanced models lies in its self-sufficient learning loop. Unlike approaches that rely on separate verifier models to evaluate intermediate reasoning (such as those in the “Search Against Verifiers” category), DeepSeek-R1 primarily uses a blend of supervised fine-tuning and direct reinforcement learning to guide and improve its own inference behavior. This internalized process of generation, reflection, and refinement equips the model with a robust and elegant approach to multi-step reasoning—entirely within a single unified framework.
Off-Policy Sampling in Language Model Training: Enabling Reward-Driven Refinement
Off-policy sampling plays a pivotal role in the reinforcement learning pipeline used to train advanced language models like DeepSeek-R1. It enables the model to explore various reasoning paths while still learning from responses not explicitly generated by the current policy—offering the flexibility needed to build robust reasoning systems without overfitting to a narrow generation pattern.
The process begins with carefully crafted prompt formatting, which is tailored to each task type. For mathematical problems, for instance, the prompts explicitly guide the model’s reasoning structure. The system instructs the model to generate intermediate logic between clearly demarcated tags, such as <THINK> and </THINK>, and to wrap the final answer in <ANSWER> and </ANSWER> tags. Moreover, the final numerical answer is often stylized using LaTeX formatting, particularly with the boxed expression $\boxed{...}$, to promote consistency and readability in outputs.
After these structured prompts are presented, the model generates multiple candidate completions—each representing a possible reasoning trajectory. These candidate outputs are then evaluated using a robust reward system.
However, not all generated outputs are perfect. It is common for early-stage completions to contain formatting errors such as missing tags, malformed LaTeX, or inconsistencies in the final answer format. During the off-policy sampling process, these formatting and structural issues are automatically detected and penalized, ensuring that the model gradually learns to adhere to the expected output conventions.
To further refine learning, DeepSeek-R1 leverages a reward optimization mechanism known as Group Relative Policy Optimization (GRPO). GRPO provides a more nuanced training signal compared to traditional reinforcement learning algorithms. It evaluates the quality of each candidate response not solely based on flawless intermediate reasoning but rather prioritizes the correctness of the final answer. This means that even if a chain-of-thought includes minor logic flaws or unconventional formatting, it may still receive a positive reward if the final answer is accurate.
This design philosophy echoes the principle seen in DeepSeek-R1-Zero: that “Reward is Enough.” By allowing minor reasoning imperfections while still encouraging correct outcomes, GRPO enables the model to incrementally improve reasoning coherence without requiring human annotation of each individual step. Over time, this approach cultivates both accurate and well-structured problem-solving behavior, which is especially crucial in complex reasoning tasks involving math, logic, or multi-step deductions.
The GRPO Algorithm Implementation: Fine-Tuning Reasoning with Policy-Based Optimization
The Group Relative Policy Optimization (GRPO) algorithm serves as the backbone of reinforcement learning in models like DeepSeek-R1, offering a finely tuned mechanism for shaping inference behavior. It builds upon the principles of Proximal Policy Optimization (PPO) — a widely adopted method in reinforcement learning — but introduces a crucial refinement: a reference policy that acts as a baseline for measuring progress and guiding adjustments.
At its core, GRPO is designed to fine-tune the model’s token generation probabilities in a way that amplifies successful reasoning patterns and suppresses ineffective ones. It does this not by judging each token in isolation, but by evaluating entire trajectories — or reasoning paths — and grouping them according to whether they lead to correct or incorrect final answers.
The intuition behind GRPO is both elegant and powerful:
- If a reasoning path produces the correct final answer, all the intermediate token decisions contributing to that path should be made more likely in future generations.
- If a path results in an incorrect answer, those token choices should be penalized, thereby reducing the probability of repeating the same mistakes.
Multi-Policy Alignment: Current, Old, and Reference
The GRPO implementation integrates three key policy references:
- Current Policy — The version of the model currently being trained.
- Old Policy — A snapshot of the model’s policy from a previous iteration.
- Reference Policy — A stable anchor that helps regularize learning, ensuring the model doesn’t drift too far from proven behavior.
These policies are used to compute the loss function — the mathematical expression that guides how the model’s parameters are updated during training. The GRPO loss is designed to:
- Respect a trust region, preventing overly aggressive policy updates that might destabilize learning.
- Optimize based on a relative advantage signal that reflects how good a particular action was compared to the model’s baseline behavior.
The Role of the Advantage Signal
The advantage parameter is a central concept in GRPO. It represents the reward differential between a generated response and what the model would have done under the reference policy. Importantly:
- If the model’s final answer is correct, the advantage is positive, even if the intermediate reasoning steps contain imperfections.
- This ensures that the model is not overly penalized for minor flaws in logic formatting, as long as it reaches a valid solution — a principle borrowed from DeepSeek-R1-Zero’s “Reward is Enough” philosophy.
This design reflects a realistic view of human-like reasoning, where intermediate steps may not always be perfect, but the ability to arrive at the correct outcome still signifies strong problem-solving capability.
Leveraging this nuanced, group-based optimization strategy, GRPO helps guide the model toward producing more accurate, coherent, and reward-aligned chains of thought — all while remaining efficient and stable in large-scale training scenarios.
Below is the implementation code that powers DeepSeek-R1’s learning process:
import torchimport torch.nn.functional as Fdef grpo_kl(pi_logprob, pi_ref_logprob): return pi_ref_logprob.exp() / pi_logprob.exp() - (pi_ref_logprob - pi_logprob) - 1def grpo_loss(pi_logprob, pi_old_logprob, pi_ref_logprob, advantage, input_len, len_oi): epsilon = 0.2 beta = 0.01 bs, seq_len = pi_logprob.shape len_oi = torch.tensor([len_oi] * bs, dtype=torch.long) mask = torch.zeros(bs, seq_len) mask[:, input_len:] = 1 ratio = torch.exp(pi_logprob - pi_old_logprob) ratio_clip = torch.clamp(ratio, 1 - epsilon, 1 + epsilon) advantage = advantage.unsqueeze(dim=1) policy_gradient = torch.minimum(ratio * advantage, ratio_clip * advantage) kl = grpo_kl(pi_logprob, pi_ref_logprob) loss = (policy_gradient - beta * kl) * mask loss = (-1 / bs) * (1 / len_oi.unsqueeze(dim=1)) * loss loss = loss.sum() return lossLoss Function Calculation in GRPO: Rewarding the Destination Over the Journey
At the heart of the GRPO algorithm lies its carefully engineered loss function, which governs how the model’s parameters are adjusted during training. This function is critical to ensuring that the model learns from both its successes and its missteps — not just at the surface level of token prediction, but across entire chains of reasoning.
The loss function operates by evaluating multiple candidate responses generated by the model, and comparing the behaviors of three different policy perspectives:
- Current Policy — The model’s present state, actively generating outputs during training.
- Old Policy — A previous snapshot of the model, used to prevent overly large updates that could destabilize learning.
- Reference Policy — A stable, often pre-trained model that serves as a benchmark for assessing improvement or regression.
These three policies interact to guide gradient updates, which incrementally improve the model’s behavior over time.
Understanding the Advantage Parameter
A key component in the loss function is the advantage parameter, which serves as the reward signal driving learning. It measures the relative value of a given candidate response by comparing its outcome to what would be expected under the reference policy.
- When the model produces a correct final answer, the advantage is positive, even if the intermediate reasoning includes flaws such as inconsistent logic or formatting errors.
- Conversely, if the final answer is incorrect, the advantage becomes negative, discouraging similar reasoning paths in the future.
This dynamic enables the model to focus learning on outcome-driven success, much like how human learners might refine a solution strategy based on the result, even if the path taken was less than perfect.
Aligning the loss calculation with this advantage-driven reward structure, GRPO ensures that training reinforces behaviors that consistently lead to correct answers, while tolerating — and gradually improving — the messiness of real-world reasoning. This balance allows for scalable, practical learning in complex domains like mathematical problem solving and structured logical tasks.
# Generate random logits for current, reference, and old policiespi_logits = torch.randn(3, 5, 32) # batch_size=3, seq_len=5, vocab_size=32pi_ref_logits = torch.randn(3, 5, 32)pi_old_logits = torch.randn(3, 5, 32)# Convert logits to log probabilitiespi_logprob = F.log_softmax(pi_logits, dim=-1)pi_ref_logprob = F.log_softmax(pi_ref_logits, dim=-1)pi_old_logprob = F.log_softmax(pi_old_logits, dim=-1)# Create example token IDstoken_ids = torch.tensor([\ [11, 12, 13, 14, 15], # Input: 11, 12, 13; Output: 14, 15\ [11, 12, 13, 15, 16],\ [11, 12, 13, 16, 17],\])# Gather the log probabilities for the specific tokenspi_logprob = torch.gather(pi_logprob, dim=-1, index=token_ids.unsqueeze(-1)).squeeze(-1)pi_ref_logprob = torch.gather(pi_ref_logprob, dim=-1, index=token_ids.unsqueeze(-1)).squeeze(-1)pi_old_logprob = torch.gather(pi_old_logprob, dim=-1, index=token_ids.unsqueeze(-1)).squeeze(-1)# Calculate the GRPO lossloss = grpo_loss(pi_logprob, pi_old_logprob, pi_ref_logprob, torch.tensor([-1, 2, 1]), 3, 2)print(loss)Stability and Regularization in GRPO: Epsilon Clipping and KL Divergence
In reinforcement learning systems like GRPO, achieving a balance between exploration and stability is crucial. While we want the model to improve and discover better reasoning strategies, we must also prevent it from making overly aggressive changes that could destabilize training. This is where two powerful mechanisms come into play: epsilon clipping and KL divergence regularization.
Epsilon Clipping: Controlling the Size of Policy Updates
The clipping mechanism, parameterized by epsilon (ε), acts as a safety guard during training. It limits how much the current policy can deviate from the old policy during an update. By enforcing this boundary, the algorithm avoids making large, destabilizing changes in response to outlier reward signals.
- Why it matters: In complex reasoning tasks, a single high reward could cause the model to overly commit to a flawed approach if not constrained. Clipping ensures that even high-reward samples don’t disproportionately influence the policy updates.
- How it works: If the ratio of the current policy to the old policy exceeds the epsilon threshold, the algorithm clips the reward signal, effectively flattening its effect and stabilizing learning.
KL Divergence: Staying Anchored While Improving
In tandem with clipping, GRPO employs a Kullback-Leibler (KL) divergence penalty as a form of regularization. This term quantifies the difference between the current policy and a reference policy (often a trusted baseline or pre-trained model).
- The KL penalty acts like a tether that gently pulls the model back toward previously learned, reliable behaviors.
- It prevents the model from drifting too far too quickly, while still allowing it to explore and improve.
By adjusting the strength of this regularizer, researchers can fine-tune how conservatively or aggressively the model learns.
Together, epsilon clipping and KL divergence form the foundation of a stable learning loop within GRPO. They ensure that updates are safe, gradual, and meaningfully guided — preserving the strengths of the model while steadily nudging it toward greater reasoning capability and performance.
The Strategic Value of Off-Policy Learning in DeepSeek-R1
DeepSeek-R1’s adoption of an off-policy learning paradigm marks a critical departure from traditional on-policy reinforcement learning strategies — and with good reason. This approach introduces a series of strategic advantages that significantly enhance both the efficiency and effectiveness of the model’s reasoning capabilities.
First and foremost, off-policy learning empowers the model to learn from a much broader set of experiences. Unlike on-policy methods that only consider the immediate outputs generated by the current policy, off-policy strategies allow DeepSeek-R1 to ingest and learn from a wider array of training data — including outputs generated by earlier policies. This diverse exposure enriches the training signals, leading to a deeper and more versatile understanding of problem-solving patterns.
Second, the framework enables the evaluation of grouped candidate responses rather than isolated output sequences. This holistic evaluation makes it easier to discern high-quality reasoning from subpar logic, giving the model a more nuanced view of what constitutes a well-structured answer.
Third, DeepSeek-R1 benefits from a streamlined training process. By removing the dependency on a separate critic network — typically required in on-policy reinforcement learning — the architecture simplifies reinforcement learning execution. This reduction in architectural complexity translates into more efficient training cycles.
Lastly, the off-policy approach encourages broader exploration of the solution space. Freed from the constraints of immediate policy feedback loops, the model can entertain a wider variety of reasoning paths. This flexibility promotes the discovery of more elegant and effective reasoning strategies, even when they initially appear less probable or are underrepresented in the training data.
Together, these factors make off-policy learning a powerful foundation for DeepSeek-R1’s growth. As training progresses, the model exhibits increasingly sophisticated chains of thought, not just in correctness, but in clarity and logical structure. The outcome is a system that performs consistently well across diverse reasoning tasks, offering step-by-step outputs that are not only accurate but also comprehensible and well-formatted.
Evaluation Techniques, Model Distillation, and the Role of Process Supervision
In the context of mathematical reasoning, evaluating a model’s performance isn’t just about checking if the final answer is correct — it involves a spectrum of methods to measure reasoning accuracy, structure, and consistency. DeepSeek-R1 leverages multiple evaluation techniques within its training pipeline to achieve this nuanced understanding:
- A basic accuracy reward mechanism is employed that uses regular expressions to extract the final answer from the model’s output and compare it directly against a known reference. If the answers match exactly, the model receives a reward score of 1.
- To allow for more flexibility and real-world mathematical variance, mathematical equivalence checking is applied using tools like HuggingFace’s Math-Verify library. This ensures that mathematically equivalent, though syntactically different, responses are also deemed correct.
- In more complex or ambiguous cases, an LLM-as-Judge strategy is used. Here, a high-capability language model (such as GPT-4o) evaluates whether two expressions are logically equivalent, returning a binary reward based on its judgment.
These evaluation scores are used to compute an “advantage” signal for each training sample, which is then normalized to have a zero mean and unit variance. Additionally, a validation step ensures the model adheres to the expected output format — catching issues like missing tags or malformed answers.
After building a powerful model like DeepSeek-R1, researchers often seek to distill its capabilities into smaller, more efficient models. This process — model distillation — is akin to a mentor-mentee relationship: the smaller model is trained via supervised learning to replicate the outputs of its larger, more capable “teacher.” Rather than learning everything from the ground up, the distilled model inherits strong reasoning patterns from the teacher, making the process more data-efficient and yielding models suitable for deployment in resource-constrained environments.
Another critical concept explored in the DeepSeek-R1 framework is process supervision. Instead of only rewarding the model for producing the correct final answer, process supervision evaluates each intermediate reasoning step, similar to how a math teacher awards partial credit for showing proper work. This method encourages more transparent and interpretable reasoning. However, defining what qualifies as a meaningful “step” can be highly subjective.
To address this, researchers employ automated tools like Math-Shepherd, MiPS, and OmegaPRM — data generation systems capable of decomposing complex problems into labeled steps. These tools help generate structured training examples that alleviate the need for manual step annotation.
Despite the sophistication of process supervision, many practitioners still lean toward “end-to-end” evaluation — assessing models solely on the final answer. This approach echoes the sentiment: “I don’t care how you got there, just get it right.” While this may sacrifice some interpretability, it often simplifies evaluation and aligns better with production demands.
This divergence reflects a broader philosophical debate in AI development: Should models be engineered for transparent, step-by-step reasoning, or should they prioritize direct accuracy, even if the reasoning process remains opaque? The answer largely depends on the intended use case, available computational resources, and the criticality of interpretability versus raw performance.
The Transformative Impact of DeepSeek-R1 on AI Reasoning
The journey from foundational techniques like STaR and Quiet-STaR to the sophisticated models DeepSeek-R1-Zero and DeepSeek-R1 reveals a compelling narrative of rapid innovation in AI reasoning. These models represent more than incremental improvements — they illustrate a fundamental evolution in how machines learn to think, reason, and solve problems in complex, multi-step environments.
At the core of this transformation is the seamless integration of autonomous exploration through reinforcement learning with structured guidance via supervised fine-tuning. In the early stages, models like STaR taught themselves to generate rationales through feedback loops. Quiet-STaR then introduced token-level reasoning control, demonstrating how even granular steps in text generation could be refined. These innovations laid the groundwork for DeepSeek-R1-Zero — a model trained entirely from scratch using reinforcement learning, drawing inspiration from AlphaZero’s success in game-playing AI.
However, DeepSeek-R1-Zero also exposed the limitations of a purely self-supervised approach. Without human-aligned objectives or formatting constraints, outputs often lacked clarity or coherence. This insight led to DeepSeek-R1 — a hybrid system that retains the exploratory nature of reinforcement learning but layers it with human-like reasoning standards through massive supervised datasets, fine-tuned reward models, and self-corrective mechanisms.
What makes DeepSeek-R1 particularly impactful is not just its performance, but the paradigm shift it embodies. Traditional models relied heavily on training-time computation, where scaling datasets and parameters was the primary path to improvement. DeepSeek-R1, by contrast, harnesses test-time computation — allowing the model to reason more deeply and allocate computational effort during inference. This enables more strategic thinking without exponentially increasing pre-training costs.
By encouraging models to “think more” at inference time — generating longer, more structured chains of thought and verifying their own reasoning — DeepSeek-R1 has redefined what’s possible in AI. It moves the field closer to systems that don’t just output answers, but arrive at them thoughtfully, with a traceable logic that humans can follow and trust.
In this light, DeepSeek-R1 isn’t merely another milestone — it’s a blueprint for the future. A future where AI systems blend the raw power of reinforcement learning with the transparency, accountability, and nuance required for real-world reasoning. As we move forward, the principles underlying DeepSeek-R1 will likely influence the design of increasingly intelligent, adaptable, and explainable AI systems across a growing range of domains.
Conclusion: Reasoning as a Frontier for General Intelligence
The evolution from early, structured approaches like STaR to the cutting-edge innovations of DeepSeek-R1-Zero and DeepSeek-R1 underscores a pivotal era in AI development—one where reasoning is no longer a peripheral feature, but the central pillar of intelligence. This transformation reflects a profound shift in philosophy: from merely scaling parameters and data to teaching models how to think, explore, self-correct, and justify their answers.
By merging reinforcement learning with process-aware training paradigms, today’s most advanced systems have not only surpassed prior benchmarks in accuracy but also demonstrated the ability to produce traceable, interpretable chains of reasoning. Approaches like test-time computation, self-refinement, verifier-guided generation, and off-policy optimization represent a complete reimagining of how language models engage with problems. These methods enable models to spend their computational effort where it matters most—during inference—crafting deeper, more reflective answers rather than relying solely on memorized associations from pretraining.
This isn’t just technical progress—it’s architectural maturity. We’re witnessing the emergence of systems that reason step-by-step, much like humans do, with the flexibility to explore multiple solution paths and the discipline to self-correct when wrong. As demonstrated by DeepSeek-R1, integrating reward-based exploration with human-aligned supervision leads to models that are not only powerful but also responsible and reliable.
Yet challenges persist. Balancing interpretability with efficiency, ensuring data quality in a world awash with noise, and deciding when to favor modular, explainable systems over end-to-end simplicity—these remain open research frontiers. But the groundwork has been laid. The innovations surveyed in this article illuminate the road ahead, showing that the future of AI lies not just in bigger models, but in smarter, more intentional, and more transparent ones.
As we move into this new phase of AI, where reasoning becomes the defining trait of useful intelligence, we owe a debt of gratitude to the researchers and engineers who pioneered this shift. Their work—spanning reinforcement learning, search-based strategies, process supervision, and hybrid optimization—has brought us closer than ever to AI systems capable of truly human-like thought.


