
Why API Standards Matter More Than Ever
In an increasingly interconnected digital ecosystem, APIs are the foundation of modern application architecture. As organizations scale their services and expose critical capabilities via APIs, maintaining consistency, reliability, and ease-of-use becomes paramount. This is where API Development Standards step in—not as bureaucratic overhead, but as accelerators of quality and innovation.
API standards are a curated set of imperatives, conventions, and practical guidance aimed at improving the consistency, stability, interoperability, and developer experience across the API landscape. They may be internal policies, industry-wide specifications, or even derived from practical lessons learned in the field.
More than just rules, API standards provide a shared framework for collaboration—between product teams, platform engineers, security experts, and business stakeholders. When implemented correctly, these standards reduce friction, improve reusability, and ensure that APIs are easy to understand, consume, and evolve.
Yet, creating effective standards requires nuance. There’s an inherent tension between the need for structured, reusable interfaces and the flexibility needed for innovation and experimentation. In large-scale enterprise environments, the goal is to strike a balance: to build APIs that are both robust and adaptable. Standards must evolve from real-world implementations, embracing feedback from teams on the ground and adapting to emerging patterns.
Adapting Standards to the Organization: One Size Does Not Fit All
While the industry offers a wealth of proven best practices and reference architectures, effective API standards are never generic. They must be customized to reflect your organization’s structure, development culture, governance model, and technology stack.
For instance, a financial institution subject to heavy regulatory scrutiny may place a premium on data classification, audit trails, and security scopes, whereas a digital-native company may prioritize rapid iteration, composability, and microservice agility. Both organizations need standards—but the nature, depth, and enforcement model of those standards will differ greatly.
That’s why a “copy-paste” approach to standards doesn’t work. The guidance in this article is not intended to be prescriptive; rather, it’s designed to spark thoughtful dialogue across your organization. Take these patterns, examine how they align with your current challenges, and adapt them to fit your team’s needs and maturity level.
Ultimately, the most effective API standards are those that:
- Respect the domain context of your APIs.
- Integrate naturally into the development lifecycle.
- Evolve iteratively based on real-world feedback.
- Enable teams, not constrain them.
Understanding MUST, SHOULD, and MAY: Clarity in API Standards
One of the most powerful tools in defining API standards is the precise use of language. The terms MUST, SHOULD, and MAY—commonly referenced from RFC 2119—carry specific implications in technical documentation and governance. When used intentionally, they help communicate the priority, enforceability, and flexibility of a given rule or recommendation.
-
MUST indicates an absolute requirement. It’s not negotiable. Any API design or behavior labeled with MUST is expected to be strictly followed. Failing to comply should result in a clear consequence, such as a failed linting rule, rejection during a pull request review, or even a blocked deployment in a CI/CD pipeline.
-
SHOULD represents a strong recommendation, but one that allows for exceptions if justified. These are best practices that, while not strictly mandatory, are expected to be followed unless there is a compelling reason not to. Ideally, violations of SHOULD guidelines trigger linting warnings, which are reviewed by a governance team or flagged for discussion during code reviews.
-
MAY implies optional behavior. These are suggestions that offer flexibility and do not trigger compliance checks. Use MAY when describing patterns or features that are beneficial in certain contexts but not universally applicable.
Be Careful with Capitalization and Consequences
When integrating these keywords into your own API documentation or internal enterprise standards, be thoughtful and consistent. Don’t capitalize MUST, SHOULD, or MAY unless you’re explicitly invoking their meaning as defined in RFC 2119.
Never label a rule with MUST unless there is a clear enforcement mechanism in place. Using the term without teeth—such as code validation, linting, or deployment policies—will undermine the credibility of your standards and cause confusion among developers.
Balance Rigor with Practicality
While it’s tempting to overuse MUST to assert control, doing so creates an unnecessarily rigid environment. A flood of hard requirements can paralyze innovation, overwhelm teams, and lead to disengagement from the standardization process.
Instead, use MUST sparingly and deliberately—reserved for critical rules related to security, naming consistency, compatibility, or regulatory compliance. Use SHOULD to encourage best practices that your team aspires to, and MAY to signal thoughtful flexibility.
In organizations just beginning their API governance journey, it’s especially important to strike a healthy balance. When linting tools generate dozens of warnings from overly broad SHOULD usage, they often go unread. Standards are only effective if they are understood, embraced, and realistically actionable.
Foundational Principles, Concepts, and Key Terms
To establish a strong foundation for API governance, it is essential to clearly define the principles, concepts, and terminology that underpin your organization’s API standards. This section sets the stage for understanding why API standards matter, who maintains them, and how stakeholders can engage in shaping their evolution.
Why Standardization Matters
API development standards serve as the compass for consistency, interoperability, and quality. In complex enterprise ecosystems, where hundreds of APIs interact across internal systems, partner platforms, and third-party consumers, a shared vocabulary and design discipline ensure predictable experiences for developers and clients alike.
Standards help avoid fragmented practices, reduce onboarding time, and promote scalable, secure, and maintainable API ecosystems. Moreover, they reduce technical debt and foster collaboration across teams by enabling APIs to act as first-class interfaces to business capabilities.
Standards should not be static—they must evolve. Therefore, each organization must assign owners or maintainers to these standards and offer a channel (e.g., Slack, GitHub discussions, Confluence comments, governance meetings) for stakeholders to provide input and request clarifications or updates.
Key Concepts and Definitions
REST — Representational State Transfer
REST is an architectural style introduced by Roy Fielding in 2000 that provides a set of principles for designing scalable, stateless, and decoupled systems. REST APIs leverage standard HTTP verbs (GET, POST, PUT, DELETE) to manipulate resources and rely on uniform interfaces to ensure interoperability and simplicity.
Due to its wide adoption, REST is the most common model used in enterprise API design, and most developers and tooling ecosystems have robust support for RESTful principles.
The REST Resource Model
The REST model describes how client systems interact with business resources over HTTP. It includes definitions of:
- Resources (e.g.,
/orders,/customers) - Operations and verbs (GET, POST, etc.)
- URI structures and paths
- Response codes and assertions
A REST model should be aligned with your domain data model, but generalized enough to enhance reusability, composability, and long-term stability. It becomes the blueprint for generating consistent API specifications—often automatically through model-driven tools.
Types of APIs and Their Roles
There are several ways to categorize APIs, but two dimensions are especially critical for governance:
Who owns the data? (source-of-truth)
Who consumes it? (developer community)
Business Resource APIs — The Source of Truth
Business Resource APIs serve as canonical sources of enterprise data. They expose core business entities like applicants, transactions, or contracts, often derived from domain-driven design.
These APIs:
- Are owned by domain teams responsible for the data
- Should be stable, discoverable, and general-purpose
- Must be secured via enterprise gateways using OAuth2, OIDC, and API scopes
- Are registered and published in the enterprise API developer portal
These APIs should represent business facts and be free of application-specific logic or filtering.
Mediating & Experience APIs — Specialized for Context
Mediating APIs—sometimes called experience or edge APIs—adapt or aggregate data from resource APIs to serve the specific needs of a frontend application or business workflow.
These APIs:
- Are often tailored to UI components (e.g., mobile apps, SPAs)
- Compose or transform data from multiple backend sources
- Might cache or format data for performance reasons
- Typically run on application-specific API gateways or edge services
Since these APIs are not sources-of-truth, caution must be used when applying resource API standards directly. Experience APIs often trade generality for performance and usability.
Understanding Developer Communities
To provide the right level of security, documentation, and onboarding experience, APIs should be categorized by target consumer.
Internal APIs
Internal APIs serve teams and applications within the organization. They:
- Are discoverable through internal developer portals
- Benefit from streamlined access control and logging
- Must maintain versioning and documentation but may support looser UX constraints
External APIs
External APIs are intended for public developers or institutional consumers. These:
- Require stricter abstraction of internal models and data
- Are exposed through secure gateways and must comply with privacy regulations
- Should be designed with simplicity and clarity, as external teams lack internal context
Partner APIs
Partner APIs are designed for trusted external collaborators and may fall into one or more of the following categories:
- Shared through federated identity frameworks (e.g., SAML, OIDC)
- Published to gated portals with approved access
- Offer deeper data visibility compared to external APIs, but under legal agreements
Maintaining separate catalogs for each audience helps ensure appropriate API discoverability, rate-limiting, and contractual guarantees.
API-First Thinking, APIs as Products, and Strategic API Governance
The modern digital enterprise no longer treats APIs as just integration artifacts or technical enablers—they are strategic assets. Embracing API-First, API-as-a-Product, and a governed API management strategy is foundational to achieving long-term agility, scalability, and interoperability.
API-First
API-First is a design philosophy where APIs are treated as the primary interface to systems and capabilities. APIs are not an afterthought to backend development—they are designed, modeled, and validated before implementation begins. This ensures APIs are purpose-built, reusable, and aligned with business intent.
By shifting left in the development lifecycle and modeling APIs upfront, teams gain:
- Clear contracts between producers and consumers
- Accelerated development through parallelization
- Stronger stakeholder engagement through early feedback
- Better alignment with enterprise architecture and security patterns
APIs as Products
When APIs are treated as products, they are designed with the consumer experience in mind—just like any customer-facing application. This means:
- APIs have a defined audience, use case, and purpose
- They are versioned, documented, and supported over time
- Success is measured by adoption, usability, and performance—not just delivery
Product mindset in API development drives intentional design, encourages ongoing evolution, and results in higher quality, more discoverable APIs.
API Management
API management is the operational backbone that supports the publication, consumption, monitoring, and governance of APIs. This includes:
- Secure API gateways for traffic routing, policy enforcement, and rate limiting
- Developer portals for discovery and subscription
- Analytics dashboards to monitor usage patterns, detect anomalies, and drive decision-making
- Lifecycle controls to manage publishing, deprecation, and retirement workflows
Modern API platforms like Apigee, Kong, MuleSoft, and Azure API Management offer enterprise-grade capabilities to handle this layer effectively.
API Governance
API governance ensures consistency, alignment, and compliance across an ever-growing catalog of services. Governance models should balance developer autonomy with enterprise alignment by establishing:
- Standards for design, security, and versioning
- Processes for peer reviews, approvals, and lifecycle transitions
- Linting and policy-as-code enforcement in CI/CD pipelines
- A culture of collaboration between platform teams and API producers
Governance should be enablement-focused, helping teams ship better APIs faster—not bureaucracy that slows delivery.
API Lifecycle Management
API lifecycle management provides a structured framework for tracking the journey of an API from concept to retirement. It defines critical phases such as design, build, test, release, support, and deprecation, while aligning cross-functional stakeholders around shared checkpoints.
Rather than being a one-size-fits-all approach, lifecycle models should be tailored to organizational needs and continuously refined. They offer visibility, structure, and quality assurance—empowering teams to manage APIs as evolving digital products.
A more comprehensive breakdown of the API Lifecycle phases, states, and CI/CD integration can be found in the [linked article].
Predictability Through Consistency
Consistent API path and naming conventions are foundational to building user-friendly, maintainable, and discoverable interfaces. They serve as the interface contract between your API and its consumers—whether internal developers, partner teams, or external clients. Inconsistent naming introduces unnecessary cognitive load and increases onboarding time for new developers, while predictable conventions empower fast integration, clearer documentation, and better automation support.
Establishing naming conventions early and enforcing them through automation (e.g., specification linting) ensures long-term scalability and organizational alignment. These conventions should align with existing enterprise standards, programming languages in use, and any relevant data dictionaries or legacy naming patterns already entrenched in your ecosystem.
Naming Fields and Parameters
For both payload fields and query parameters, a consistent casing strategy must be adopted across all APIs. The two most common styles are:
-
lowerCamelCase – preferred in JavaScript and most web ecosystems
Example:"givenName": "Alice" -
snake_case – common in Python and certain data-intensive platforms
Example:"given_name": "Alice"
Select one and mandate it across your organization. This consistency allows for cleaner client code generation, easier mapping between systems, and improved readability in logs and monitoring dashboards.
Additional field name best practices:
- Use descriptive and semantically meaningful names. Avoid generic names like
"value"or"data". - Arrays should use plural nouns to indicate multiple entries, e.g.,
"colors": ["red", "blue"].
Resource Naming and Path Conventions
RESTful API design relies heavily on clear, resource-oriented paths. Resource names serve as the verbs and nouns of your API and must follow intuitive and consistent naming patterns.
-
Collections: Use plural nouns to represent a set of resources
Example:/users,/orders,/applications -
Instances: Use singular form when referencing a specific entity within a collection
Example:/users/123,/applications/456 -
Sub-resources: When an entity has a logical child or nested component, it should appear as a singular noun
Example:/users/123/profile,/orders/456/shipping
Avoid action-based paths like /getUser or /createOrder—these violate REST principles and obscure resource orientation. Instead, use HTTP methods (GET, POST, PUT, DELETE) to describe the operation.
URI Formatting and Hyphens
In URI paths:
- Use hyphens (
-) to separate words:/business-contacts - Avoid underscores (
_) and camelCase in URI paths—they reduce readability in browser bars and logs - For naming inside JSON payloads or query parameters, align with your chosen field naming convention (e.g., lowerCamelCase or snake_case)
URI Example:
https://api.example.com/v1/customer-ordersThis format is readable, descriptive, and clearly versioned. It aligns with RESTful practices and helps clients intuitively understand the API surface.
Clear naming conventions form the backbone of a usable API and are critical to long-term maintainability. While it’s tempting to prioritize flexibility, standardization is what allows large-scale reuse, governance, and automation to succeed.
Resource Identifiers
A resource identifier is a core concept in RESTful API design—it’s the unique handle that distinguishes one specific resource from another. These identifiers are the backbone of routing, linking, caching, and access control in modern APIs.
To ensure robustness and future-proofing, resource identifiers must be immutable. Once assigned to a resource, an identifier should never change, regardless of the resource’s state or updates. This guarantees consistency across references, bookmarks, logs, and client integrations.
While identifiers can be numeric (e.g., 12345) or string-based (e.g., "abc123"), there are several best practices that modern APIs should adopt:
- Identifiers must be URL-safe: Avoid special characters and unsafe encoding. Base62 or UUID formats are common.
- Avoid sequential or guessable IDs: Sequential IDs (e.g.,
user/1,user/2, …) can expose sensitive information about system scale and user activity. Use opaque or randomized formats (e.g.,"u-923jfhd8","48c2-91b3") to abstract underlying database structures and protect against enumeration attacks. - Never embed Personally Identifiable Information (PII) or primary keys in your identifiers.
These practices reinforce principles of abstraction, security, and scalability, making APIs more resilient to future architectural changes and integrations.
Resource References
Resource identifiers often appear not only in the URL path but also in payloads—especially in nested or related resources. To maintain consistency and clarity, a standardized convention for referencing identifiers across the API must be adopted.
There are two common approaches:
Minimalist referencing using "id":
{ "id": "12B34C" }This pattern is clean and works well when the resource type is already clear from context, such as the endpoint path (/users/12B34C).
Explicit referencing using resource-qualified identifiers:
{ "customerId": "12B34C" }This approach is more verbose but eliminates ambiguity, especially in complex response documents with multiple nested references.
When referring to external resources (e.g., foreign keys, related entities, parent-child relationships), the explicit naming convention should always be used, such as:
{ "orderId": "34C56D", "productId": "X9283F" }This naming style improves readability, simplifies code generation, and aligns with common object modeling standards. It also eliminates the need for developers to infer meaning from undocumented “id” fields, particularly in aggregated or nested structures.
Tip: Standardize on a single naming pattern for external references (e.g., <resourceName>Id) across your API suite. This reduces developer friction, improves searchability, and helps with automated schema validation and enforcement.
Adopting consistent and secure identifier conventions is critical to building scalable, interoperable APIs. These conventions enhance clarity, reduce ambiguity, and future-proof your systems against internal architectural shifts.
Standardized Encoding
To ensure compatibility across systems and platforms, UTF-8 (Unicode Transformation Format - 8) is the required encoding for all text-based API payloads, including string data and textual representations in structured formats like JSON. UTF-8 is also the default encoding for JSON as specified in RFC 7159, and should be treated as the baseline standard for all enterprise and public-facing APIs.
Exceptions to UTF-8 encoding are strongly discouraged and must only be considered for partner or internal APIs in scenarios where strict technical constraints prohibit its use. In such cases, alternative encoding formats must be clearly documented and approved through the appropriate architectural governance process.
Interoperable and Consistent Data Formats
To promote interoperability, reuse, and developer experience, enterprise APIs must adhere to consistent data formatting practices. These practices eliminate ambiguity, reduce integration friction, and simplify client-side parsing and validation.
The following conventions must be observed:
-
Media Type: All APIs — both newly designed and significantly updated — MUST support
application/jsonas the baseline media type. This ensures broad support, simplicity, and alignment with common client libraries. Support for additional formats likeapplication/xmlorapplication/pdfmay be provided as optional extensions based on use case requirements. -
Date-Time Formats: All APIs must express date and time values in a standardized format compliant with RFC 3339, a profile of ISO 8601 designed for internet protocols.
Example:
2025-05-27T14:45:00ZThis ensures unambiguous representation of timestamps across systems, including correct time zone handling.
-
Boolean and Enumerated Values: Booleans must be expressed using native
trueorfalseliterals, not strings or numeric equivalents. Enumerations should use well-defined and documented string values, not integers, to improve readability and reduce risk of misinterpretation. -
Shared Domain Vocabulary: Common entities such as
address,person, ororganizationSHOULD align with shared enterprise domain models or archetypes. This enables consistency across APIs and encourages reuse of client-side models, improving integration efficiency.
Structuring Request and Response Documents
A predictable and consistent structure for request and response payloads is fundamental to creating intuitive, reliable, and developer-friendly APIs. Standardized document layouts help client developers navigate complex data models more easily, reduce implementation errors, and streamline integration efforts — particularly in enterprise ecosystems where APIs are composed and reused across domains.
Where regulatory or industry-specific standards (such as HL7, ISO 20022, or NIEM) apply, their structural patterns and constraints MUST be observed to ensure compliance. However, in the absence of such mandates, enterprise APIs should strive for simplicity, clarity, and cohesion in their document design.
Principles for Effective Payload Structure
-
Flat and Lean by Default: Avoid deeply nested or overly complex hierarchies unless semantically necessary. Favor flatter structures that improve readability and simplify serialization and deserialization logic for client libraries.
-
Express Composability Through Modularity: Structure payloads so that components (e.g.,
address,contactDetails,employmentHistory) can be reused across resources. This aligns with composable architecture principles and supports consistent modeling across domains. -
Align with Domain and Conceptual Boundaries: The organization of data in the request and response documents should reflect the conceptual contours of the business domain. For example, distinguish clearly between entities (nouns) and actions (verbs), and encapsulate related properties within coherent objects.
-
Explicitly Define Optional vs. Required Fields: Request payloads should distinguish required and optional fields clearly, helping clients construct valid input documents while providing flexibility for extensibility.
-
Minimize Ambiguity: Avoid polymorphic or context-sensitive field structures that require custom logic to interpret. Instead, be explicit in field purpose, naming, and value format.
-
Consistent Error Structure: All error responses across APIs should follow a shared format (e.g.,
code,message,details) to allow for standardized client-side error handling and diagnostics.
Request and Response Protocols
Establishing clear, consistent HTTP protocol conventions across APIs is essential for interoperability, security, and a predictable developer experience. These conventions ensure that client applications behave consistently, errors are handled gracefully, and APIs remain resilient and secure in enterprise environments.
The following sections outline protocol-level best practices and standards that should be adopted across the organization.
HTTPS Only
All API endpoints MUST be exposed over HTTPS with TLS encryption. Cleartext HTTP should be strictly disallowed in all environments, including development and internal testing, to prevent accidental exposure of sensitive information and ensure alignment with enterprise security policies and compliance mandates (e.g., PCI-DSS, HIPAA, GDPR).
HTTP Methods
A consistent and RESTful use of HTTP methods improves the clarity of intent for both human developers and automated tooling. Organizations should provide explicit guidance for the following:
- GET – Retrieve resource representations. Must be idempotent and safe.
- POST – Create new resources. Used for submission operations and may return 201 Created with a
Locationheader. - PUT – Replace an entire resource. Must be idempotent and validate full request body integrity.
- PATCH – Apply partial updates to a resource. Highly useful for targeted field updates but should be used cautiously and documented clearly.
- DELETE – Remove a resource. Use with discretion; some business domains may prefer soft deletes (e.g., status updates) over physical deletion.
- HEAD – Retrieve metadata about a resource without the response body. Recommended for internal monitoring and health check endpoints.
Where business services choose not to support methods such as DELETE or PATCH, the rationale should be documented — such as regulatory compliance, auditing requirements, or immutability constraints.
HTTP Request and Response Headers
Standardizing required and recommended headers improves interoperability and security:
-
Common Request Headers:
Accept– Specifies desired media type (e.g.,application/json)Authorization– Bearer token for OAuth2 or API keyContent-Type– Must be set for any payload-carrying request (e.g.,application/json)
-
Recommended Response Headers:
Content-Type– Describes the returned media typeCache-Control– Defines caching behaviorETag– For optimistic concurrency controlX-Correlation-ID– Traces a request across microservicesRetry-After– Used in conjunction with 429 or 503 for throttling guidance
Headers that are required for all APIs should be mandated and enforced by specification linting and gateway policies.
HTTP Response Status Codes
Response codes provide clients with unambiguous indicators of outcome. The following conventions should be documented and aligned with each supported method:
- 200 OK – Successful GET, PUT, or PATCH operation
- 201 Created – POST resulted in resource creation
- 204 No Content – DELETE or successful operation with no body
- 400 Bad Request – Client error in request syntax or validation
- 401 Unauthorized – Authentication required or failed
- 403 Forbidden – Authenticated but not authorized
- 404 Not Found – Requested resource does not exist
- 409 Conflict – Versioning conflict or constraint violation
- 422 Unprocessable Entity – Validation passed, but semantics invalid
- 429 Too Many Requests – Rate limit exceeded
- 500+ Server Errors – Internal service issues
APIs should avoid ambiguous or misused status codes and provide meaningful error payloads aligned with the enterprise error format.
Response Caching
Proper use of HTTP caching can dramatically improve API performance and reduce backend load — but it must be applied deliberately to avoid stale or incorrect data:
- Use
Cache-Controlheaders (no-cache,max-age,must-revalidate) to define explicit client and proxy behavior. - Leverage
ETagandLast-Modifiedfor conditional requests and change detection. - Caching should be enabled only for idempotent operations (e.g., GET, HEAD), and never for mutable operations (e.g., POST, PUT).
- Carefully assess caching strategies when APIs expose sensitive or dynamic business data.
A consistent caching policy across APIs avoids unpredictable behavior and helps developers optimize client-side and intermediary usage.
Error Handling
Effective error handling is a cornerstone of robust API design. While standard HTTP status codes offer a succinct and widely accepted way to communicate high-level outcomes (e.g., 400 Bad Request, 403 Forbidden, 500 Internal Server Error), they often fall short in delivering actionable insights for diagnosing and resolving issues. In enterprise contexts—where system complexity, scale, and interdependencies are high—developers and support teams require …
Use Standard HTTP Status Codes as a Foundation
APIs MUST return the appropriate HTTP status code for each response, as it ensures consistency across the ecosystem and compatibility with developer tooling and intermediaries (e.g., proxies, API gateways, monitoring platforms).
However, status codes are inherently coarse-grained. For example:
400 Bad Requestcould reflect a range of issues—invalid payload structure, semantic business rule violations, missing required parameters, etc.500 Internal Server Errormight result from backend system outages, database failures, or unhandled application exceptions.
For these reasons, a consistent, structured approach to error response payloads is recommended in enterprise APIs.
Structured Error Responses
When detailed error payloads are introduced, business resource APIs should follow a standardized schema. This ensures predictability and usability across the developer community, while avoiding overexposure of internal implementation details that could present security risks.
A best-practice pattern is to include an errors top-level array in the response body. Each item in this array should provide enough context to:
- Communicate the type and category of the error
- Assist in correlation with server-side logs or tracing tools
- Reference the specific field or component in the request that caused the failure
- Help consumers take corrective action where applicable
Example structure:
{ "errors": [ { "errorId": "85024bfe-a602-7b3c-82be-301e7d0bd0a6", "origin": "myDomain.myApp", "code": "EMM-7b3c82be", "message": "Data validation error", "detail": "Future date not allowed", "source": "profile.birthDate" } ]}Field Definitions
- errorId: A unique identifier (UUID) for the error instance, allowing easy correlation with internal logs and traces.
- origin: The source domain or application component where the error originated.
- code: A machine-readable error code, ideally mapped to internal knowledge bases or documentation.
- message: A brief, human-readable description of the error type.
- detail: Optional contextual information providing specifics on what caused the error.
- source: An optional pointer to the request field or element that triggered the error, often represented in dot notation.
Enterprise Logging and Observability
While structured error responses enhance the developer experience, they are not a substitute for proper observability infrastructure. Logging, tracing, and monitoring systems should be the primary tools for diagnosing issues within the service landscape. Correlation IDs (e.g., X-Correlation-ID) and trace identifiers should be returned in response headers and logged consistently across all services.
This dual approach ensures:
- Internal teams can trace and resolve issues without needing exhaustive error responses
- External or partner developers have sufficient information to correct client-side errors or engage support with a reference
Security Considerations
Avoid exposing sensitive implementation details, internal stack traces, or proprietary logic in error responses. These may inadvertently provide threat actors with valuable reconnaissance data.
Only include fields in the structured response that are explicitly approved by the enterprise security governance process. Treat error message design with the same scrutiny as API response schema.
Security by Design: Embedding Protection from the Start
Modern API ecosystems demand a security-first approach, where protection is not an afterthought but is built into every stage of the API lifecycle—from design through deployment. This Security-by-Design principle ensures that APIs are governed by robust security controls aligned with the sensitivity of the data they expose and the regulatory environments they operate within.
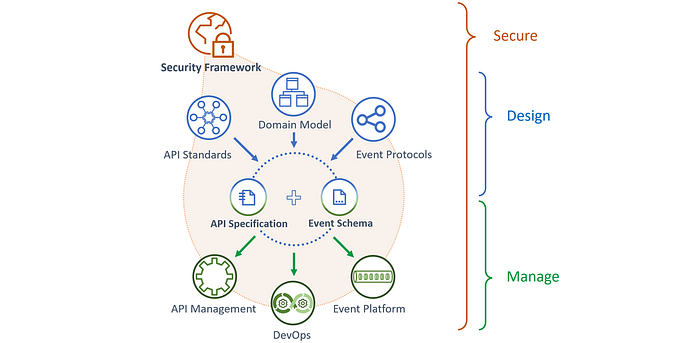
Data Classification and Regulatory Alignment
Security starts at the modelling phase, where data is classified according to its sensitivity (e.g., public, internal, confidential, restricted) and regulatory implications are mapped (e.g., PCI-DSS, GDPR, HIPAA). This upfront classification allows teams to implement data-specific controls early and consistently.
Model-Derived Security Controls
Business services responsible for data ownership implement fine-grained security controls informed by the classification model. The domain model should capture these security attributes explicitly, enabling API specifications to inherit enterprise-standard security schemes automatically—ensuring alignment across all services and reducing manual errors.
These controls include:
- Data redaction
- Token-based access controls
- Multi-factor enforcement
- Transport-layer encryption
- Rate limiting and throttling for abuse prevention
Protecting Resource APIs with API Scopes
API scopes are a powerful mechanism to apply granular access control at the API layer, leveraging the OAuth2 and OIDC standards while enhancing them for enterprise-grade authorization workflows.
Understanding API Scopes
API scopes define what operations a client application is authorized to perform on a specific business resource. They extend the OAuth2 “scope” concept and are supported by most API gateways and OpenAPI 3 (OAS3) specifications.
For example:
security: - oauth2: - profile.read - transactions.writeThese scopes can be enforced at the API gateway, enabling coarse-grained decisions such as:
- Is this client registered and authorized for this scope?
- Is this user allowed to perform this operation?
Dual-Layer Access Control
Security does not end at the gateway. Within the business service itself, fine-grained access decisions must be made based on the identity and entitlements of the user:
- Gateway check (coarse): Is the client allowed to call the API?
- Service check (fine): Is the end-user permitted to access or act on this specific data?
This dual-layer control ensures that least privilege access is enforced across both system and user boundaries.
Fortifying Sensitive APIs: Tactical Security Practices
Protecting sensitive APIs requires a comprehensive, multi-layered approach that spans architectural abstraction, transport security, robust access controls, and rigorous testing. These tactics form the foundation of enterprise-grade API security, enabling organizations to reduce risk, ensure compliance, and preserve customer trust.
API Abstraction and Identifier Design
Sensitive APIs must never expose underlying implementation details. This includes obfuscating internal identifiers that could reveal business logic, infrastructure design, or user data patterns. To that end:
- Resource Identifiers must be:
- Non-sequential: Avoid numeric sequences (e.g.,
user/1001) that could be guessed or scraped. - Un-guessable: Use UUIDs or similarly strong identifiers (e.g.,
user/3fa85f64-5717-4562-b3fc-2c963f66afa6). - Opaque: Ensure they reveal nothing about Personally Identifiable Information (PII), system architecture, or data origin.
- Non-sequential: Avoid numeric sequences (e.g.,
This abstraction minimizes surface area for enumeration attacks and makes it harder for malicious actors to infer structure or access unauthorized data.
Enforcing Transport Layer Security
Transport layer encryption is non-negotiable for all enterprise APIs. Best practices include:
- HTTPS-only Exposure: All API endpoints must be published using TLS encryption — plain HTTP must be disallowed at both ingress and egress.
- TLS Version Enforcement: Enforce TLS 1.3 or TLS 1.2, depending on client compatibility. Older, insecure versions must be disabled.
- Mutual Authentication (mTLS): For particularly sensitive internal or partner APIs, implement mTLS to authenticate both client and server identities.
- API Gateway Enforcement: Lock down APIs to only be accessible via approved API Gateway(s), where policies can be uniformly enforced.
Ensuring Data Confidentiality, Integrity, and Non-Repudiation
Data flowing through sensitive APIs may be governed by legal, regulatory, or contractual controls — particularly in domains like financial services, healthcare, or government. To safeguard against data breaches or misuse:
- Confidentiality: Ensure encrypted storage and transmission of all sensitive fields.
- Integrity: Use checksums, digital signatures, or hash validations where required to detect tampering.
- Non-repudiation: Leverage signed audit trails, tokenization, and consistent logging to verify action provenance and compliance readiness.
When dealing with region-specific laws (e.g., GDPR, HIPAA, PSD2), carefully consult legal and compliance teams to implement appropriate data handling tactics consistently across systems.
Proactive Security Testing and Automation
Security must be shifted left — integrated into the development lifecycle from the outset. Tactics include:
- Policy-as-Code Automation: Codify security, naming, and documentation policies into CI/CD pipelines to enforce consistency and prevent regressions.
- Dynamic and Static API Testing: Implement OWASP top 10 API-specific test coverage (e.g., BOLA, excessive data exposure, mass assignment).
- Specification-Driven Fuzzing: Use OpenAPI schemas to generate fuzzing tests that can uncover edge-case vulnerabilities.
- Continuous Vulnerability Scanning: Run regular scans across API environments for exposed secrets, known CVEs, and configuration weaknesses.
API Gateway Security and Defense-in-Depth
API gateways should act as the first line of defense, enforcing centralized and standardized security measures across all APIs. Capabilities to be leveraged include:
- Rate Limiting & Throttling: Prevent abuse and denial-of-service (DoS) attacks by controlling request velocity.
- IP Whitelisting & Geo-blocking: Limit access to known and trusted IP ranges or geographic regions.
- OAuth/OIDC Integration: Enforce robust client and user authentication via token validation and scope enforcement.
- Payload Schema Validation: Reject malformed or out-of-spec requests at the edge to reduce downstream risk.
Combining these layers with in-service application logic provides a strong defense-in-depth strategy and guards against both external and insider threats.
Enterprise Logging, Tracing, and Audit Strategy
Robust logging, tracing, and auditing are foundational pillars of enterprise-grade API governance. While API management platforms offer centralized visibility into traffic and high-level usage metrics, they often fall short in delivering the depth, granularity, and integration required to troubleshoot, monitor, and secure complex distributed systems. Every large and growing organization must adopt a cohesive API logging strategy that incorporates Security Information and Event Management (SIEM), distributed tracing, and secure audit practices.
Distributed Tracing for End-to-End Visibility
Modern enterprises operate in a microservices ecosystem where requests traverse multiple components. To observe and troubleshoot this complexity, a standardized and scalable tracing framework is essential. OpenTelemetry, aligned with the W3C Trace Context specification, provides a vendor-neutral foundation for distributed tracing.
Benefits include:
- End-to-End Contextualization: Enables precise correlation of API calls across services, queues, and infrastructure boundaries.
- Accelerated Incident Resolution: Developers gain immediate access to relevant trace data, reducing time to resolution and avoiding ticket escalations or log spelunking.
- Systemic Insights: Facilitates root cause analysis and visualizes system behavior under load, revealing latency bottlenecks, retries, and interdependencies.
- Secure Troubleshooting: Allows client and platform teams to investigate issues without relying on verbose error responses, which can be sanitized or suppressed at the gateway level for security.
Read more: OpenTelemetry and W3C Trace Context
Audit Logging and SIEM Integration
A mature API ecosystem integrates with enterprise-wide Security Information and Event Management (SIEM) platforms to proactively detect and respond to potential threats. Security-relevant events such as:
- Authentication successes and failures
- Authorization decisions and scope checks
- Anomalous usage patterns (e.g., brute-force API calls, IP mismatches)
- Data access events involving protected resources
…must be logged in real time with appropriate granularity and metadata, enabling actionable alerts, forensic investigations, and compliance audits.
A well-integrated SIEM platform transforms logs into insights, correlating them across services, users, and devices, while supporting automated response workflows where applicable.
Secure Logging Practices
Security and privacy risks can arise when sensitive data is logged improperly. API gateways and business services must follow secure logging principles to ensure that logs remain a source of truth—without becoming a source of leakage.
Key practices include:
- Redaction and Masking: Always sanitize logs to strip out or mask sensitive content—this includes access tokens, API keys, passwords, and Personally Identifiable Information (PII).
- Allow-List Character Filtering: Implement strict allow-listing of loggable characters to defend against log injection attacks and scripting exploits.
- Classified Data Retention Policies: Only log classified or regulated data (e.g., PCI, HIPAA, GDPR) in approved systems designed for secure storage, and ensure logs are encrypted both in transit and at rest.
- Avoid Logging Full Payloads: In general, avoid storing raw payloads unless critical for debugging and explicitly permitted by policy. Instead, log metadata (e.g., trace ID, user ID, resource ID, status code) to preserve context.
Event-Driven Logging Across the Lifecycle
An effective enterprise API logging strategy is not an afterthought—it is deeply integrated into the full lifecycle of API design, implementation, and operations. From trace headers embedded at the request level, to audit trails tied to user actions and automated alerts surfaced in SIEM dashboards, logging should empower teams to observe, trust, and continuously improve their APIs.
Together, distributed tracing, centralized security logging, and audit-level compliance form a resilient foundation for API observability, governance, and operational excellence.
API Health Checks
In a microservices and API-driven architecture, health checks are essential for ensuring service availability, operational transparency, and reliable system orchestration. They enable infrastructure platforms, API gateways, monitoring tools, and DevOps teams to assess the readiness and liveliness of individual APIs and the services behind them.
Health checks serve two primary purposes:
- Liveness checks — Is the API up and running at the most basic network level?
- Readiness checks — Is the API ready to handle requests successfully, including dependent services and data access?
A well-defined health check strategy should consider where and how health information is exposed, how it is consumed, and how it aligns with enterprise monitoring, automation, and service discovery standards.
TCP Open Checks (Liveness)
TCP-level health checks validate that the service is reachable and can accept network connections on a specific port. This is the most basic form of service health, and typically used by load balancers, ingress controllers, or platform orchestrators (e.g., Kubernetes, ECS, etc.).
- Purpose: Confirms the application process is up and reachable.
- Limitations: Does not verify that application logic or downstream dependencies (e.g., databases, third-party APIs) are functioning correctly.
TCP checks are useful for coarse-grained infrastructure orchestration but should be complemented by higher-order checks.
HTTP HEAD or GET-Based Health Checks (Readiness)
An HTTP-based health check uses the HEAD or GET method to query a specific API endpoint (often /health, /status, or /readiness) to assess service operational health.
HEADchecks are efficient, returning headers only (no body), and can be used to validate that a specific API path is responding appropriately.GETchecks can provide a richer response body, often including service metadata, status of dependencies (e.g., database connectivity, third-party APIs), application version, or even configuration hash checks.
Example response:
{ "status": "UP", "appVersion": "2.3.5", "dependencies": { "database": "UP", "authService": "UP", "thirdPartyApi": "DEGRADED" }, "timestamp": "2025-05-27T08:30:45Z"}Health Check Strategy
When defining a health check approach across the enterprise, consider:
- Standardize the endpoint path (e.g.,
/health,/readiness) and method (HEAD, optionallyGET) for consistency and automation support. - Differentiate between system-level and application-level checks, especially if APIs depend on downstream services or shared platforms.
- Avoid exposing sensitive internal information (e.g., internal IPs, stack traces) in public-facing health check responses.
- Align with cloud-native and DevOps tooling — support Kubernetes probes (
livenessProbe,readinessProbe), monitoring agents (e.g., Prometheus), and CI/CD checks.
When Are Health Checks Mandatory?
Health check support should be mandatory for APIs that:
- Are exposed externally through enterprise gateways or consumed by partners.
- Play a critical role in business workflows or customer-facing applications.
- Are deployed in containerized, cloud-native platforms requiring orchestration and scaling.
Internal or utility APIs may not require formal health checks but should follow the enterprise conventions if implemented.
Reliable, standardized API health checks are fundamental to maintaining a resilient and observable API ecosystem. They empower automation, reduce downtime, and provide DevOps teams and platform tools with the insights needed to maintain service quality.
By integrating TCP-based and HTTP-based health checks into the API lifecycle, enterprises enable smarter scaling, faster incident response, and better orchestration across their API estate. Consistency in implementation ensures that all stakeholders—from SRE teams to monitoring platforms—can confidently interpret and act on health signals from any service.
Final Thoughts: Driving Excellence Through Governed API Standards
To enable true interoperability across decentralized systems and autonomous domains, organizations must adopt governed, opinionated API design standards and patterns. These standards are not meant to restrict innovation, but rather to foster cohesion, predictability, and reusability at scale—laying the foundation for robust enterprise-wide integration and sustainable digital transformation.
This guidance provides a framework of proven conventions and best practices, but there is no one-size-fits-all solution. Every enterprise has its own legacy systems, domain architectures, and operating realities. Therefore, the real power of API standards lies in their thoughtful adaptation—ensuring alignment with enterprise context while maintaining a clear, consistent contract between service providers and consumers.
Successful standards emerge not from ivory towers but from collaborative iteration. Engage architects, developers, security teams, and domain experts early and often. Validate design principles in real implementation scenarios, and refine your standards as your systems evolve. Encourage open feedback loops and build your standards body as a living, breathing source of truth.
Above all, remember that standards are strategic assets. They reduce onboarding friction, accelerate delivery, safeguard interoperability, and improve governance. With clear guidance and continuous improvement, your organization can unlock the full potential of APIs—turning technical consistency into a competitive advantage.


