
Why Serverless Compute & Serverless Database Make Sense for Region-Specific Deployments
In our architecture, the decision to adopt serverless compute and serverless databases is driven by the nature of our use case: it’s inherently event-driven and stateless. This means operations are only required when specific triggers occur—such as when a product is added or updated in the inventory. There’s no need for continuously running compute resources, and that alone translates into significant cost savings and reduced operational complexity.
Let’s take a practical example. When a new product is uploaded to the system:
- The product image is stored in an object store like Amazon S3.
- A serverless function is automatically triggered, which:
- Processes the image,
- Resizes it for various resolutions,
- Extracts metadata such as dimensions or dominant colors,
- Validates and stores attributes like name, description, price, and stock count.
- The processed product metadata is then saved to a region-local serverless database (such as DynamoDB or Firestore, depending on cloud vendor).
This architecture ensures that we only incur compute costs when these discrete operations are triggered. If we were using traditional server-based infrastructure, we’d need to:
- Keep compute resources running 24/7 to listen for such events.
- Handle auto-scaling, provisioning, maintenance, patching, and redundancy manually.
- Pay for idle resources even when there’s no activity.
With serverless compute, such as AWS Lambda or Google Cloud Functions, compute resources are ephemeral and on-demand. They spin up automatically in response to events, execute the required logic, and shut down immediately afterward. This model is perfectly suited for our needs, as most of our backend tasks are stateless and triggered by asynchronous events.
Likewise, serverless databases like DynamoDB, Aurora Serverless, or Firestore are built to automatically scale based on demand, handle replication across regions, and offer millisecond read/write latency—all without manual tuning or provisioning. They are optimized for workloads that:
- Have spiky or unpredictable traffic,
- Require low-latency access within a region,
- And benefit from pay-per-request pricing.
By deploying this infrastructure regionally, we further reduce latency for end users in different geographies while taking advantage of the cloud’s native redundancy, availability zones, and managed failover mechanisms.
In summary, serverless compute and databases are ideal for event-driven, stateless, and regionally distributed systems. They allow us to:
- Eliminate idle costs,
- Focus purely on business logic,
- Avoid operational overhead,
- And scale seamlessly based on usage patterns.
Now, let’s explore the architecture diagram that ties all this together.
Orchestrating Global Inventory with Serverless Architecture
In a modern, distributed retail infrastructure, managing product inventory across global stores requires more than just a reliable database. It demands a responsive, scalable, and cost-efficient architecture—qualities inherently provided by a serverless design.
When a new product is added to the inventory system, it triggers a serverless function. This lightweight, event-driven function springs into action only when required. It processes the product information—validating fields such as the title, description, and SKU—and handles supplementary tasks like resizing the product image or extracting metadata from it. Once processed, the data is stored in a serverless database that’s deployed locally within the same cloud region where the event originated.
This regionalized approach is essential. By keeping compute and data within the same geographical boundary, the system minimizes latency, improves performance, and isolates faults—ensuring uninterrupted operation even if other regions experience issues. Each regional store can query its local serverless database to determine product availability, aiding real-time decisions for restocking and managing on-shelf inventory.
However, the architecture doesn’t stop at regional optimization. It intelligently extends to a global scale. As updates occur—whether a product is added, updated, or removed—specific data is streamed from the regional serverless databases to a centralized cloud region. This central database serves as the master inventory dataset, providing a unified, enterprise-wide view of product availability across all retail locations.
This global perspective is crucial for business intelligence. By consolidating product data from all regions, companies gain insights for demand forecasting, trend analysis, and operational planning. Whether it’s preparing for a seasonal sales spike or identifying underperforming SKUs, the centralized database enables data-driven decisions.
That said, this approach comes with design considerations. Data transfer across cloud regions isn’t free. Cloud providers typically charge for outbound data movement, making it imperative to be selective. The architecture must ensure that only essential data—often aggregated, filtered, or summarized—is transferred to the central repository to avoid unnecessary cost overhead.
In essence, this serverless architecture harmonizes two competing needs: regional autonomy and global intelligence. It enables localized services to operate independently while feeding centralized analytics that shape enterprise strategy. It’s lean, it’s responsive, and it’s designed for a world where events—not servers—drive computation.
Evolving System Requirements: Integrating Real-Time Retail Transactions
The initial serverless architecture was a success. By enabling production warehouses to update product data directly into region-specific serverless databases, the organization achieved real-time visibility into its inventory across global locations. This system offered a lightweight, scalable solution that handled updates only when triggered by warehouse activity—ensuring cost efficiency and minimal operational overhead.
But as the system matured, a new challenge emerged.
The company now aims to unify inventory tracking not only from the production side but also from the retail front. To accomplish this, the regional serverless databases—originally intended just for product updates—are being elevated to act as the single source of truth for inventory information. This shift introduces a critical new requirement: integration with the retail shops’ in-store systems, including IoT-enabled devices at checkout counters.
Here’s how the new system works:
Each time a customer makes a purchase at a retail store, the store’s local system emits an event. This event is picked up by a new retail transaction serverless function, which is also deployed in the same cloud region. The function is responsible for processing the transaction and updating the product count directly in the existing serverless inventory database—right alongside warehouse updates.
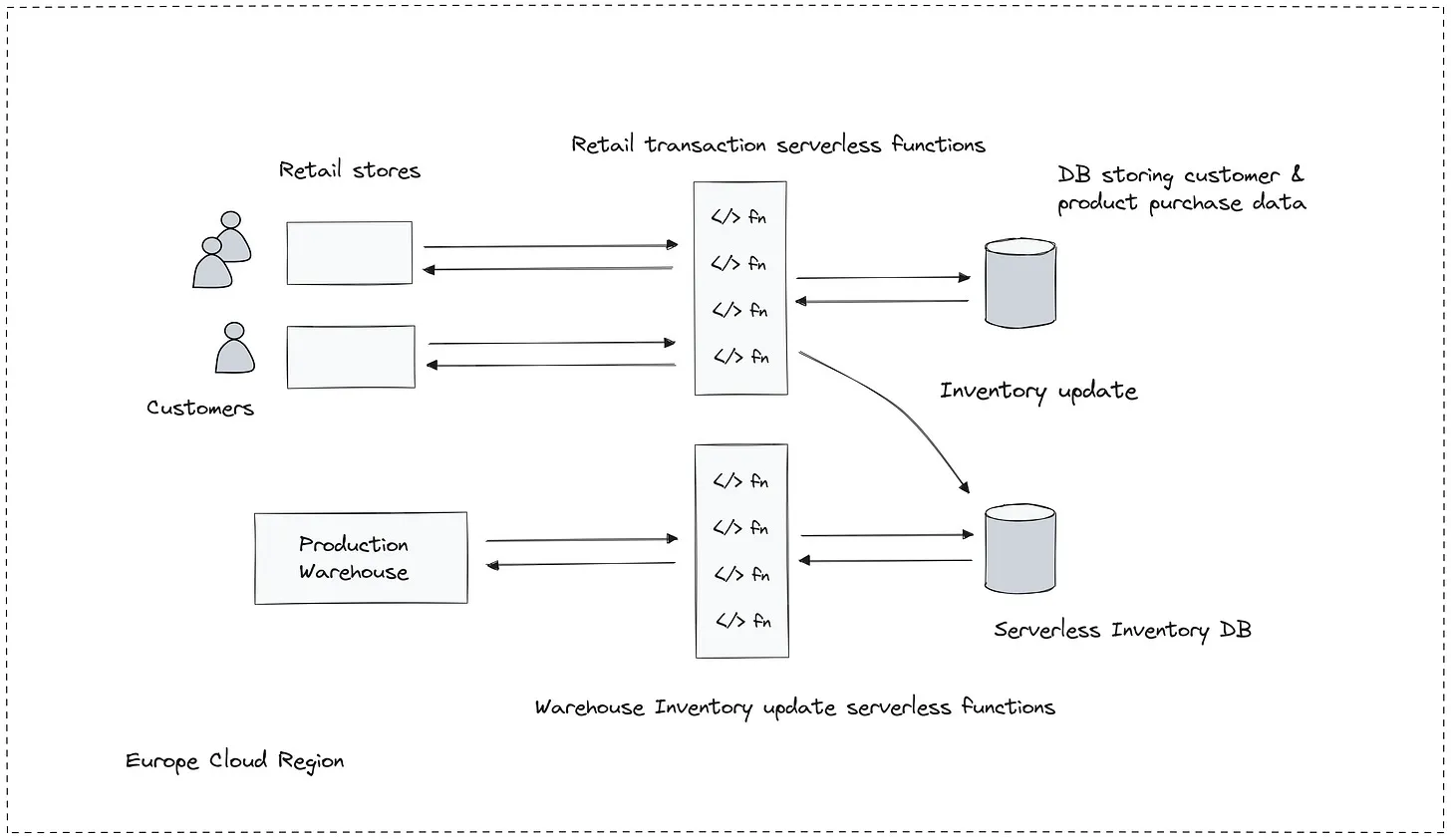
This architectural enhancement yields multiple benefits:
- Unified Inventory Management: Instead of maintaining separate databases for warehouse and retail transactions, a single inventory database in each cloud region now serves both use cases.
- Real-Time Stock Accuracy: As purchases happen, inventory is instantly updated, reducing discrepancies between physical stock and digital records.
- Simplified Architecture: There’s no longer a need for complex sync mechanisms or middleware to reconcile data between two systems. This not only cuts operational overhead but also minimizes points of failure.
- Scalability: Since each retail event triggers a lightweight function, the system scales naturally with traffic. Whether it’s a quiet weekday or a peak-season rush, the architecture flexes without bottlenecks.
However, this new use case introduces one critical nuance: statefulness.
Unlike the earlier warehouse scenario, which was stateless and transactional, retail purchase events may require context and continuity. For example, a purchase might be part of a broader transaction that includes multiple products, applied discounts, or promotional logic. To manage this effectively, the system must retain some session-level data or historical context during execution. Enter stateful serverless functions—a newer evolution in the serverless paradigm that supports ephemeral or long-lived state during processing.
By combining stateless and stateful compute patterns, the system now provides a full-spectrum solution for global inventory management—from product stocking to point-of-sale tracking—all while retaining the cloud-native benefits of elasticity, simplicity, and cost optimization.
Retail Transaction Serverless Architecture: From Event Triggers to Stateful Processing
In the modern retail environment, IoT-enabled infrastructure plays a vital role in driving automation, efficiency, and real-time responsiveness. Our retail stores are no exception—equipped with IoT devices that trigger backend events for every meaningful interaction. Whether it’s a product sale, an update to customer preferences, or transactional behavior, these events must be handled promptly and intelligently.
At the heart of this architecture are serverless functions designed to respond to these retail events. But unlike stateless event processors used in earlier stages (such as product uploads from warehouses), many retail use cases require stateful processing.
Why stateful? Consider these examples:
- A purchase event might be part of a larger multi-item transaction.
- A customer’s buying pattern may influence real-time recommendations.
- Long-lived sessions might involve tracking abandoned carts or promotions over time.
Storing state within serverless functions enables such advanced capabilities by reducing dependency on external databases for transient or session-specific data. This improves latency by avoiding repeated roundtrips to the database and offloads pressure from the core storage infrastructure.
While serverless is traditionally associated with statelessness, it’s a misconception that serverless must be stateless. With the advent of stateful serverless runtimes, we can now build far more sophisticated systems without losing the benefits of elasticity and simplified deployment.
Alongside the inventory database (which handles stock updates), our retail backend also integrates a customer database. This database manages:
- Customer profiles and preferences
- Transaction histories
- Purchase analytics
- Loyalty programs and regional behavior patterns
Depending on the architecture, this customer data can be streamed synchronously or asynchronously to the central cloud region. This stream feeds into global analytics engines that allow the business to:
- Understand buying trends in specific regions
- Compare performance across retail locations
- Optimize supply chains based on aggregated data
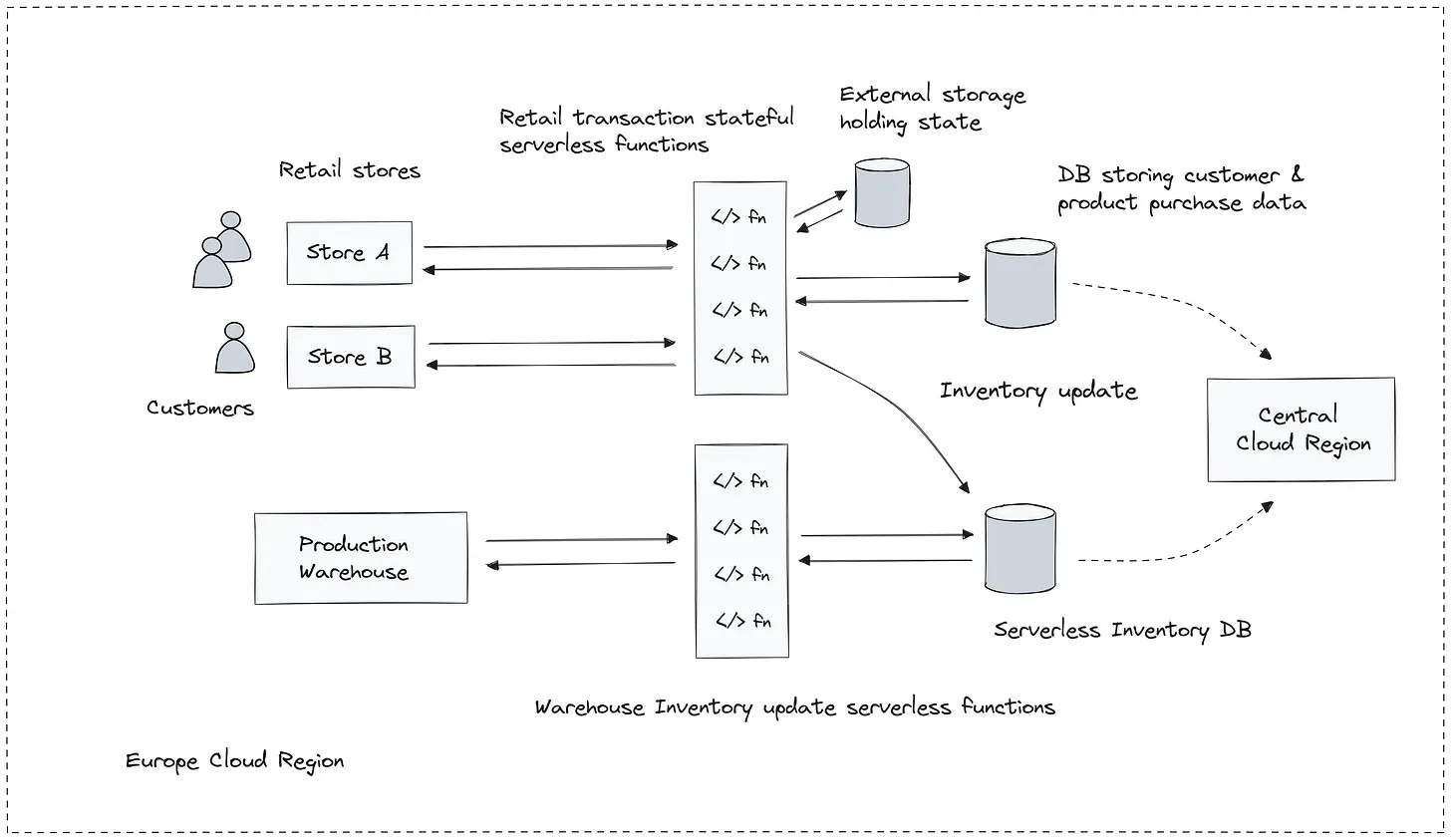
This dual-database strategy—one for operational data (inventory) and one for analytical and customer-specific data—forms a powerful foundation for intelligent retail automation. It allows us to:
- Maintain real-time stock accuracy
- Personalize user experiences at the edge
- Streamline reporting to corporate systems
Ultimately, this architecture blends the reactive nature of event-driven systems with the robustness of stateful processing and serverless infrastructure—paving the way for responsive, scalable, and cost-efficient retail technology.
Separating Stateless and Stateful Serverless Functions for Clarity and Optimization
In designing scalable serverless systems, it’s essential to clearly delineate between stateless and stateful serverless functions based on the nature of the workload and operational requirements.
For instance, product updates originating from production warehouses are straightforward, event-driven tasks that involve no long-term memory or context across invocations. These are ideal candidates for stateless serverless functions. These functions are lightweight, ephemeral, and well-suited for handling short-lived operations like:
- Adding a new product to inventory
- Updating existing product details such as price or description
- Uploading and processing product images
Because they don’t maintain any context between executions, stateless functions can scale out horizontally and independently, making them highly efficient for discrete, transactional tasks.
In contrast, retail product purchases involve more complex scenarios that often span multiple user actions or require memory of prior events. These use cases demand stateful serverless functions capable of retaining context across invocations. Examples include:
- Managing a customer’s multi-item purchase journey
- Tracking order statuses over time
- Managing loyalty points or purchase-based recommendations
These functions are designed to be long-lived and context-aware, with mechanisms to persist state either in-memory, in a temporary store, or through integration with purpose-built backend systems.
Why Keep Them Separate?
- Separation of Concerns: Each function type serves a fundamentally different purpose. Separating them avoids unnecessary complexity in the codebase.
- Optimized Scaling: Cloud platforms can independently monitor, scale, and allocate resources to each function type depending on usage patterns and load characteristics.
- Deployment Flexibility: Stateless and stateful workloads can be deployed, versioned, and updated independently without risk of interfering with each other’s performance.
- Security and Resource Boundaries: Stateless functions often require fewer permissions and less memory, while stateful functions may need access to session data or user profiles. Keeping them separate helps enforce the principle of least privilege and minimizes the attack surface.
Distinguishing these functions architecturally and operationally, we build a more resilient, performant, and maintainable serverless environment. This separation also allows teams to iterate independently and focus optimization efforts based on the unique characteristics of each workload.
Expanding on Stateful Serverless Functions: When and Why to Use Them
In traditional serverless computing, functions are stateless by default. Each invocation is isolated, and the function does not retain memory of any previous request. However, modern application needs often involve workflows, transactions, and sequences of interactions that do require memory—leading to the rise of stateful serverless functions.
What Are Stateful Serverless Functions?
Stateful serverless functions are designed to maintain and access state across invocations. Unlike stateless functions that treat each event as atomic and disconnected, stateful functions allow developers to build long-running, session-aware, and workflow-oriented services in a serverless environment.
To support this model, cloud providers and frameworks enable state retention through two primary mechanisms:
1. External State Storage
To persist state across multiple function invocations, stateful serverless functions integrate with external low-latency storage systems, such as:
- Distributed key-value stores (e.g., Redis, DynamoDB)
- Low-latency NoSQL databases
- Cloud-native state stores offered by the serverless platform
These systems are optimized for fast read/write access, ensuring that state can be quickly updated and retrieved between requests without compromising performance.
2. In-Memory Storage During Execution
For short-lived, request-scoped memory, many serverless platforms offer in-memory state storage during a function’s active execution. This is ideal for temporarily caching frequently accessed data or tracking transient state that doesn’t need to persist across invocations. It improves system responsiveness by reducing trips to external storage during processing.
3. Integrated Platform-Managed State
Certain advanced serverless platforms natively support built-in state management tied directly to the function execution model. For example:
- Azure Durable Functions extend Azure Functions with reliable state, enabling developers to define stateful orchestrations across multiple function calls using durable task patterns.
- Apache Flink Stateful Functions offer built-in state co-location with event sources, using Flink’s powerful distributed runtime to provide consistent, fault-tolerant state handling with high scalability and minimal developer overhead.
In these models, the platform manages the state lifecycle internally, abstracting away the complexity of connecting to and maintaining external storage systems. Developers simply define the state shape and usage pattern, and the platform ensures durability, scalability, and recovery.
How Is State Maintained Across Requests?
To identify and associate requests with their corresponding state:
- The system stores a unique identifier (e.g., session ID, client ID, or auth token).
- This key is used to retrieve the associated state from memory or an external store.
- Upon subsequent requests, the serverless platform leverages this key to reload the previous context for the same client or session.
This mechanism enables features like:
- Personalized sessions (e.g., shopping carts)
- Event-driven workflows (e.g., onboarding flows)
- Long-running business processes (e.g., order fulfillment, data pipelines)
Why Add State to Serverless Functions?
If serverless is designed to be ephemeral and stateless, why introduce state into the mix? Why not stick to traditional API-based backends?
The answer lies in developer agility, system simplicity, and resource efficiency.
Benefits of Stateful Serverless Functions
-
Reduces System Complexity: Instead of building a separate orchestrator service or bolting on external databases for every stateful use case, developers can encapsulate logic and state into a single function definition.
-
Simplifies Orchestration: Complex, multi-step workflows (e.g., approvals, retries, conditional paths) can be implemented declaratively using serverless orchestrators like Azure Durable Functions or AWS Step Functions.
-
Improves Scalability: The serverless platform manages the infrastructure. You only pay for what you use. It automatically handles scaling, failover, and state persistence without the need for custom backend logic.
-
Faster Time to Market: Developers focus on business logic rather than infrastructure or session management.
-
Better Resource Isolation: Each stateful function operates within a sandboxed environment, which enhances security, fault isolation, and multi-tenant deployment capabilities.
When Should You Use Stateful Serverless Functions?
Use them when:
- You need to manage long-lived workflows
- Your logic depends on session context or historical data
- You want to implement retry or compensation logic
- You’re working with event-driven architectures that involve user interactions across time
- You’re building resilient distributed workflows
Avoid them when:
- Your application is purely stateless and transactional
- You need ultra-low latency and the overhead of managing state introduces delays
- You require fine-grained control over state synchronization or consistency, better suited to custom backends
Stateful serverless functions bridge the gap between the agility of serverless and the complexity of stateful business logic. With modern serverless frameworks evolving to support built-in or pluggable state handling, developers can now create rich, event-driven, state-aware applications without sacrificing scalability or speed of deployment.
Navigating the Choice: Serverless vs. Conventional API-Driven Backend
When designing systems for modern, scalable applications, one of the most important decisions you’ll make is choosing between a serverless architecture and a conventional API-driven backend. This isn’t a decision that should be made by default or based solely on trends—it requires a thoughtful analysis of your business goals, workload characteristics, and operational constraints.
In our particular case, the path to serverless wasn’t chosen for novelty. It was chosen because it aligned with the very nature of our system: event-driven, cost-sensitive, and highly dynamic.
Our application doesn’t need to run continuously. It doesn’t stream videos, maintain live user sessions, or manage persistent client connections. Instead, it reacts to specific events—like a product being added to the inventory or a customer making a purchase in a retail store. These operations happen sporadically and are highly transactional. This makes serverless a near-perfect fit. We don’t pay for idle compute, and we don’t have to provision servers that sit unused waiting for the next request. Instead, compute is triggered when it’s needed, and only then.
But the value of serverless goes deeper. Beyond cost savings, there’s the simplicity of not having to manage infrastructure. There’s no need to manually configure load balancers, autoscaling rules, or worry about hardware provisioning. Those responsibilities are abstracted away by the cloud provider. As developers, we get to focus on writing business logic, not infrastructure automation.
Even with the need for state—yes, even in a model that’s classically “stateless”—modern serverless platforms have evolved. With stateful serverless functions, we can persist session information, track long-lived transactions, and even orchestrate complex workflows without reverting to a traditional backend. Platforms like Azure Durable Functions and Apache Flink Stateful Functions are prime examples of how state management can be woven into the fabric of serverless environments in an efficient and scalable way.
Of course, this doesn’t mean serverless is universally better. In fact, there are important caveats. If our system required persistent connections—say, to support WebSockets or live collaboration tools—the ephemeral nature of serverless functions would make things difficult. These types of applications typically demand a conventional backend that can maintain long-lived sessions and granular control over network behavior.
Similarly, if we needed low-level control over our compute environment—tuning memory, configuring custom runtime behavior, or managing highly specialized infrastructure—a traditional API-driven backend would offer the flexibility we’d need.
There’s also the matter of vendor lock-in. Serverless platforms tie you closely to a specific cloud provider’s services, APIs, and infrastructure. While this can accelerate development and reduce operational burdens, it can also make future migrations more complex. If you decide to switch cloud providers or change architectural direction, you might find yourself needing to refactor significant portions of your codebase.
That’s why, when it comes to choosing between these two paradigms, the most pragmatic approach is to build a proof of concept. Test your assumptions. Measure performance. Evaluate latency, cost, and developer productivity in both scenarios. Let data guide your decision—not just preference or hype.
In our case, serverless—with stateful capabilities—proved to be a perfect match. It allowed us to respond to real-world events with minimal cost, effort, and overhead, while still supporting the nuanced needs of a stateful retail transaction system. But in your case, the answer might be different. And that’s okay. The key is understanding your needs and designing for them intentionally.
Because at the end of the day, good system design isn’t about picking the trendiest tech—it’s about building systems that scale, adapt, and serve the business well.
Final Thoughts: Building Systems That Scale with Purpose
As we navigate the evolving landscape of cloud-native architectures, it’s easy to get swept up by trends or default to popular frameworks. But true engineering maturity lies in making intentional choices—balancing trade-offs, understanding your system’s needs, and architecting for resilience, performance, and maintainability.
Whether you’re leaning toward serverless, a conventional backend, or a hybrid approach, your goal should always be to solve real problems with clarity and precision. Serverless architectures shine in event-driven, stateless, and cost-conscious environments, while traditional backends offer depth, control, and persistence when complexity demands it.
Ultimately, the best architecture is not the one that’s hyped, but the one that aligns with your use case, scales with your users, and adapts with your business.
Build deliberately. Measure obsessively. Evolve continuously.


