
Rethinking Kafka at Scale — Tiered Storage and Its Implications for System Design
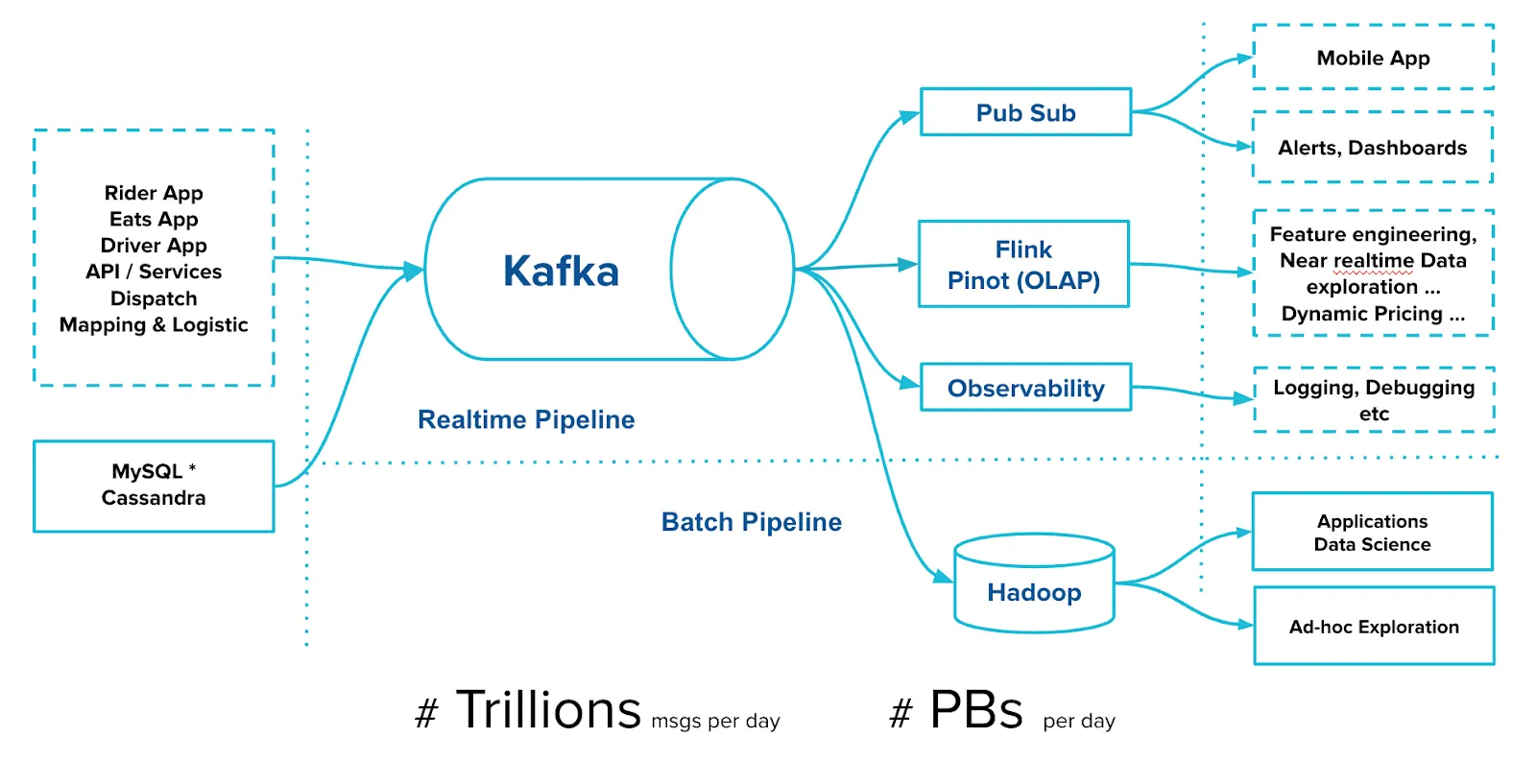
Kafka is foundational to Uber’s data architecture, underpinning critical systems for both batch and real-time processing. However, as data volumes surge and retention requirements grow, the traditional Kafka architecture — where storage and compute are tightly coupled — introduces significant friction.
At the core of Kafka’s scalability challenge is the fact that storage capacity scales linearly with the number of broker nodes. If you need to store more data, you must add more brokers — and with them, more CPU and memory resources — even if you only require storage. This results in inefficient resource utilization, increased costs, and operational complexity that hampers agility and makes deployments harder to scale or maintain.
Uber identified these issues early and proposed a robust architectural solution: Kafka Tiered Storage, as detailed in KIP-405. This enhancement introduces a dual-tier architecture:
- Local Tier: Fast-access, low-latency storage that resides on the Kafka broker’s local disk.
- Remote Tier: Extended, lower-cost, longer-term storage typically implemented using cloud object storage like S3, GCS, or HDFS.
This design fundamentally decouples compute and storage, allowing Kafka to scale storage independently of compute resources. Not only does this reduce hardware overhead and improve resource efficiency, but it also simplifies operations and enables Kafka clusters to retain data for longer periods without bloating broker nodes or requiring aggressive data purging.
Why It Matters
This separation aligns with modern architectural paradigms, especially those seen in serverless, lakehouse, and decoupled data processing systems. By treating Kafka as a durable, long-lived event log, the architecture becomes much more flexible — enabling use cases that go far beyond real-time messaging.
With native support for remote storage, Kafka transitions from being just a transient message bus into a streaming backbone with persistent capabilities. This opens the door to using Kafka not just for event transport, but for event retention and replay, auditing, state recovery, and even as a system of record in certain scenarios.
Kafka as a System of Record?
The natural follow-up question is: can Kafka replace a database?
The short answer is not always, but sometimes — yes.
Kafka is a distributed, append-only, immutable log. This immutability makes it ideal for systems where preserving the complete history of events is important — for example, compliance, audit trails, or temporal analytics. In fact, many modern architectures already project current state from Kafka streams, using stateful processors or materialized views.
However, unlike a traditional database, Kafka does not natively support:
- Rich query capabilities (e.g., SQL joins or secondary indexes)
- Schema enforcement beyond what Schema Registry provides
- ACID transactional semantics for data manipulation
Despite this, some companies have successfully adopted Kafka as a source of truth. A prime example is KOR Financial, a fintech firm that deliberately replaced traditional databases with Kafka. Their architecture captures both events and state transitions via Kafka streams, processing hundreds of petabytes of data with long-term retention powered by Confluent Cloud’s tiered storage. Read more here.
For them, the trade-offs made sense: simplified infrastructure, reduced operational overhead, and the ability to model complex event-driven workflows without duplicating state between Kafka and a database.
The introduction of tiered storage is a pivotal moment in Kafka’s evolution. It signals a shift toward treating Kafka as not just a message broker but as a core component of enterprise data architecture. By enabling persistent, cost-effective, and scalable storage, Kafka is now positioned to serve a wider range of roles — including that of a lightweight system of record.
Still, this architecture isn’t for everyone. For teams exploring this path, it’s crucial to assess:
- Data access patterns
- Retention requirements
- Query complexity
- Regulatory and compliance constraints
But if your architecture is already Kafka-centric, and if you prioritize event sourcing, immutability, and high-throughput durability over traditional RDBMS features — Kafka + Tiered Storage might be all you need.
Using Kafka as a Database – Is It Viable?
As Kafka matures and becomes more central in data architectures, a natural question arises: Can Kafka replace a traditional database? This isn’t just a thought experiment. Enterprises exploring event-driven systems often find themselves evaluating whether Kafka’s durability, immutability, and event replay capabilities can serve database-like functions.
An excellent reference on this topic is the Confluent blog post, which dives deep into the mechanics, implications, and trade-offs of using Kafka in a database-like role.
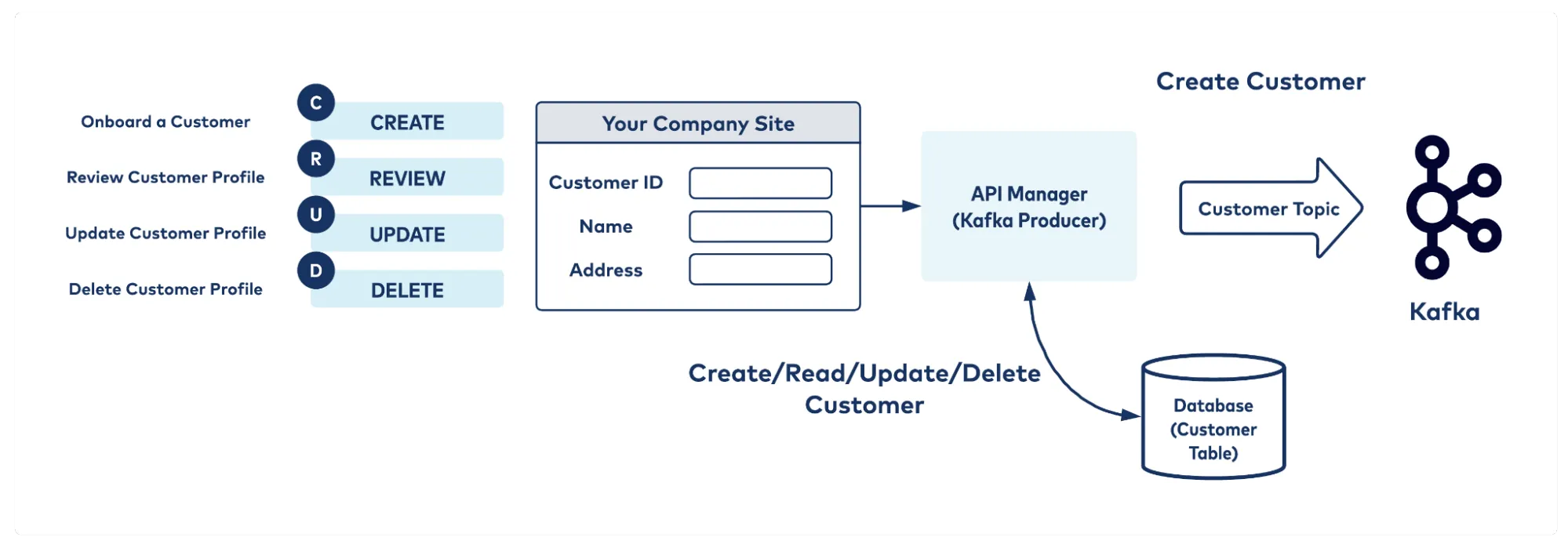
Kafka and the CRUD Model
At its core, a database is designed to support Create, Read, Update, and Delete (CRUD) operations with stateful consistency. In the Confluent example, a CRUD service captures all such operations and emits them as Kafka events via a producer. These events are then consumed downstream — typically by consumers that persist state, such as a database or an event processor.
Here’s how it plays out:
- Create operations are logged as new Kafka messages.
- Update operations don’t overwrite old values; instead, they append new records indicating the updated state.
- Delete operations are also appended, marking the deletion event — not removing the original record.
Unlike a relational database where an UPDATE or DELETE modifies the final state, Kafka is an immutable log. Each operation is added to the log sequentially, preserving the entire history.
This design brings transparency and traceability, but it also introduces challenges. For example, determining the latest state of an entity in Kafka requires aggregating all relevant events, either via stream processing or state stores.
ksqlDB – Bridging the Gap
To mitigate some of these limitations and bridge the gap between stream processing and database-style interactions, Confluent introduced ksqlDB — a database abstraction built on top of Kafka.
With ksqlDB, you can:
- Define materialized views (i.e., tables) over Kafka topics
- Use SQL-like syntax to query, join, and aggregate event streams
- Maintain state over time and treat a Kafka stream as a continuously updating table
This means you can simulate database-like functionality directly on top of Kafka without persisting data into a traditional database — all while retaining the benefits of Kafka’s immutability and event replay.
When Kafka Acts Like a Database — And When It Shouldn’t
Using Kafka in place of a database works best in architectures that are:
- Event-sourced: where maintaining the full history of changes is essential
- Immutable by design: where you never need to overwrite or delete data
- Stream-oriented: where real-time processing is more valuable than querying historical data
However, Kafka should not be viewed as a replacement for:
- Transactional systems requiring ACID guarantees
- Rich query workloads with complex joins and filtering
- Use cases needing strict consistency or relational integrity
Final Thoughts
Kafka excels as a durable, distributed, high-throughput log that can persist, replicate, and replay data at scale. Combined with tools like ksqlDB, Kafka can take on many responsibilities traditionally handled by databases — especially in systems that prioritize auditability, event lineage, or stream processing.
But it’s important to be pragmatic. Kafka wasn’t designed as a database. Rather than forcing it into that mold, use its strengths to augment traditional databases or serve as the source of truth in event-driven systems.


